PL/SQL, PL/pgSQL기본 개념 이해하기
PL/SQL이란 무엇인가
-
절차적인 처리가 가능하다.
SQL 구문만으로는 실행하기 어려운 복잡한 처리가 실행할 수 있다. 예를 들면 어떤 데이터를 검색하고 그 데이터를 조건으로 하여 레코드를 갱신할지 말지 판단하는 일련의 처리를 실행할 수 있다. -
오라클과의 친화성이 높다.
오라클에서 개발한 절차적(Procedural Language for SQL) 프로그래밍 언어이기 때문에 오라클에서 사용 가능한 모든 데이터 타입을 지원한다. 따라서 SQL과 PL/SQL 사이의 데이터 타입 변환 작업이 필요 없다. -
이식성이 높다.
OS가 무엇이든 오라클이 동작하는 환경에서라면 PL/SQL 구문을 수정하지 않고도 실행할 수 있다. -
퍼포먼스 측면에서 유리할 수 있다.
프로그래밍 언어에서 여러 SQL 구문으로 처리하는 경우에는 다양한 미들웨어를 거치면서 오라클 서버와 통신하기 때문에 실행하는 SQL 구문의 수가 많을수록 오버헤드가 걸릴 수 있는 반면 PL/SQL은 블록에 포함된 다양한 SQL를 하나의 프로그램 단위로 실행하여 전송하기 때문에 오버헤드를 줄일 수 있다. PL/SQL 블록에 네임을 붙어주면 오라클 내부에 구문 분석이 완료된 상태로 저장해둘 수도 있는데(Stored) 이렇게 해두면 구문 분석이 생략되어 부하를 더 줄일 수도 있다.
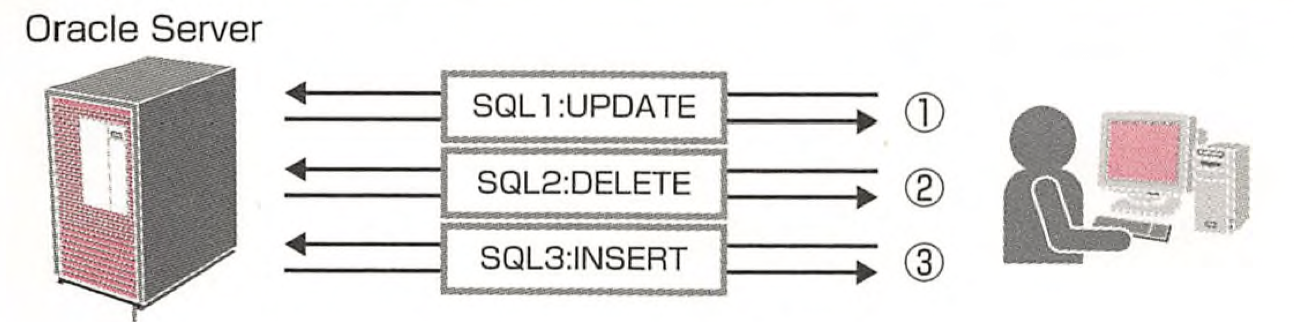
👆SQL 단위로 처리하는 경우 Image from プロとしてのOracle PL/PSQL入門

👆PL/SQL 블록 단위로 처리하는 경우 Image from プロとしてのOracle PL/PSQL入門
PL/SQL 구문의 기본 구조
DECLARE, BEGIN, END 사이에 중첩 구조(Nested)가 있다고 해도 논리적으로는 1개의 블록으로 취급된다.
<<label>> -- this is optional
DECLARE
-- this section is optional
number1 NUMBER(2);
number2 number1%TYPE := 17; -- value default
text1 VARCHAR2(12) := 'Hello world';
text2 DATE := SYSDATE; -- current date and time
BEGIN
-- this section is mandatory, must contain at least one executable statement
SELECT street_number
INTO number1
FROM address
WHERE name = 'INU';
EXCEPTION
-- this section is optional
WHEN OTHERS THEN
DBMS_OUTPUT.PUT_LINE('Error Code is ' || TO_CHAR(sqlcode));
DBMS_OUTPUT.PUT_LINE('Error Message is ' || sqlerrm);
-- nested block
DECLARE
BEGIN
END;
-- nested block end
END;
사용 가능한 데이터 타입
- NUMBER
- CHAR
- VARCHAR2
- DATE
- BOOLEAN
- Composite 타입 (RECORD, TABLE, VARRAY 등)
사용 가능한 구문
- 조건문 (IF ELSIF ELSE END IF;)
- CASE문 (CASE WHEN … THEN END CASE;)
- LOOP문
%TYPE, %ROWTYPE 속성
PL/SQL을 사용하다보면 테이블에서 검색한 데이터를 직접 변수에 대입하는 경우가 자주 있는데 오라클의 데이터를 직접 취급하는 경우에 대응하는 변수를 %TYPE, %ROWTYPE으로 정의하면 매우 편리하다.
%TYPE, %ROWTYPE 속성은 데이터 타입을 직접 지정하는 것이 아니라 오라클 컬럼의 데이터 타입이나 이미 정의돼 있는 변수의 데이터 타입을 참조한다.
DECLARE
var dept.deptno%TYPE;
BEGIN
SELECT deptno INTO var from dept
WHERE loc = 'SEOUL';
DBMS_OUTPUT.PUT_LINE(var);
위 예제에서 var라는 변수의 데이터 타입은 dept.deptno%TYPE으로 정의돼 있는데 이는 dept라는 테이블의 deptno 컬럼과 동일한 데이터 타입을 사용하겠다는 의미다.
%TYPE 속성
특정한 테이블의 컬럼에 정의된 데이터 타입을 참조한다. 기본 형식은 <변수명> <테이블명>.<컬럼명>%TYPE;
%ROWTYPE 속성
%TYPE 속성이 특정한 테이블의 컬럼에 정의된 데이터 타입을 참조하는 데 반해 %ROWTYPE 속성은 테이블(또는 뷰)의 행 구조를 참조한다. 따라서 %ROWTYPE 타입의 변수는 각 컬럼의 데이터를 저장하기 위해 행 구조와 동일한 수의 필드 영역을 확보하고 각 컬럼의 이름과 데이터 타입을 그대로 참조한다.

👆PL/SQL 블록 단위로 처리하는 경우 Image from プロとしてのOracle PL/PSQL入門
PL/SQL의 종류
- 익명 블록 (PL/SQL anonymous block)
- 함수 (Function)
- 프로시저 (Procedure)
- 패키지 (Package)
- 트리거 (Trigger)
익명 블록 (PL/SQL anonymous block)
<<label>> -- this is optional
DECLARE
-- this section is optional
number1 NUMBER(2);
number2 number1%TYPE := 17; -- value default
text1 VARCHAR2(12) := 'Hello world';
text2 DATE := SYSDATE; -- current date and time
BEGIN
-- this section is mandatory, must contain at least one executable statement
SELECT street_number
INTO number1
FROM address
WHERE name = 'INU';
EXCEPTION
-- this section is optional
WHEN OTHERS THEN
DBMS_OUTPUT.PUT_LINE('Error Code is ' || TO_CHAR(sqlcode));
DBMS_OUTPUT.PUT_LINE('Error Message is ' || sqlerrm);
END;
- DECLARE, BEGIN, EXCEPTION, END 키워드로 이루어져 있으며 각 키워드는 선언부, 실행부, 예외처리부분을 담당하는 블록으로 구성돼 있다.
- 초기값을 지정하지 않은 변수는 NULL 값이 디폴드로 들어간다.
:=는 대입 연산자다.
함수 (Function)
CREATE OR REPLACE FUNCTION <function_name> [(input/output variable declarations)] RETURN return_type
[AUTHID <CURRENT_USER | DEFINER>] <IS|AS> -- heading part
amount number; -- declaration block
BEGIN -- executable part
<PL/SQL block with return statement>
RETURN <return_value>;
[Exception
none]
RETURN <return_value>;
END;
- 함수는 어떤 연산을 거치고나서 단일한 값(single value)을 반환(return)하려는 목적에서 쓰인다.
- 반환 값으로는 숫자, 날짜, 문자열 같은 스칼라 값이 될 수도 있고 nested 테이블이나 배열 같은 단일 컬렉션(single collection)이 될 수도 있다.
- 함수는 SQL문 내에서 실행 가능하다. 오라클 내장함수인 SYSDATE, LENGTHB 같은 것을 사용하는 SQL문이 그런 경우다. (이 점이 프로시저와 가장 크게 다른 점이기도 하다.)
프로시저 (Procedure)
CREATE PROCEDURE create_email_address ( -- Procedure heading part begins
name1 VARCHAR2,
name2 VARCHAR2,
company VARCHAR2,
email OUT VARCHAR2
) -- Procedure heading part ends
AS
-- Declarative part begins (optional)
error_message VARCHAR2(30) := 'Email address is too long.';
BEGIN -- Executable part begins (mandatory)
email := name1 || '.' || name2 || '@' || company;
EXCEPTION -- Exception-handling part begins (optional)
WHEN VALUE_ERROR THEN
DBMS_OUTPUT.PUT_LINE(error_message);
END create_email_address;
- 프로그램 유닛의 이름이 가지고 있어서 반복해서 호출될 수 있다는 점에서는 함수와 비슷하지만 SQL 구문 내에서 사용될 수 없다는 점에서 다르다.
- 함수는 단일한 값을 반환하는 반면에 프로시저는 다수의 값(multiple)을 반환할 수 있다.
프로시저의 파라미터 모드 (IN, OUT, IN OUT)
- IN 모드는 디폴드 모드로 참조 값을 통해서 IN 파라미터 변수에 대입된다.
- OUT 모드는 프로그램이 종료되는 시점에 파라미터에 대입된 값이 호출된 프로그램으로 반환된다.
CREATE OR REPLACE PROCEDURE triangle( base IN NUMBER DEFAULT 10, height IN NUMBER DEFAULT 20, area OUT NUMBER ) IS BEGIN area := (base * height) / 2 END; / - IN OUT 모드는 하나의 파라미터가 IN과 OUT 모두의 역할은 하는 것이다.
함수와 프로시저의 차이
| 프로시저 | 함수 | |
|---|---|---|
| 반환값의 수 | 복수 | 하나 |
| 반환값 지정 | OUT, IN OUT 파라미터 | RETURN 구문 |
| 파라미터 모드 | IN, OUT, IN OUT | IN |
| SQL문에서의 사용 가능 | 불가 | 가능 |
| 트랜잭션 제어 (COMMIT 등) | 가능 | 불가 |
| 변경 처리 (DML) | 가능 | 불가 |
의존성 문제

프로시저 proc1은 함수 func1를 호출하고 함수 func1은 테이블 tab1를 참조하는 상황에서 각 오브젝트 간에 의존-참조 관계가 형성된다. 오라클에서는 USER/ALL/DBA_DEPENDENCIES 딕셔너리 뷰를 조회하여 의존 관계를 확인하고 의존 관계가 깨진(INVALID) 오브젝트에 대해서는 USER/ALL/DBA_OBJECTS의 STATUS 컬럼을 조회해봄으로써 재컴파일 필요성 여부를 점검하게 된다.
# 수동으로 다시 컴파일 하는 경우
ALTER <오브젝트 종류> <오브젝트 명> COMPILE;
ALTER PROCEDURE pro1 COMPILE;
패키지 (Package)
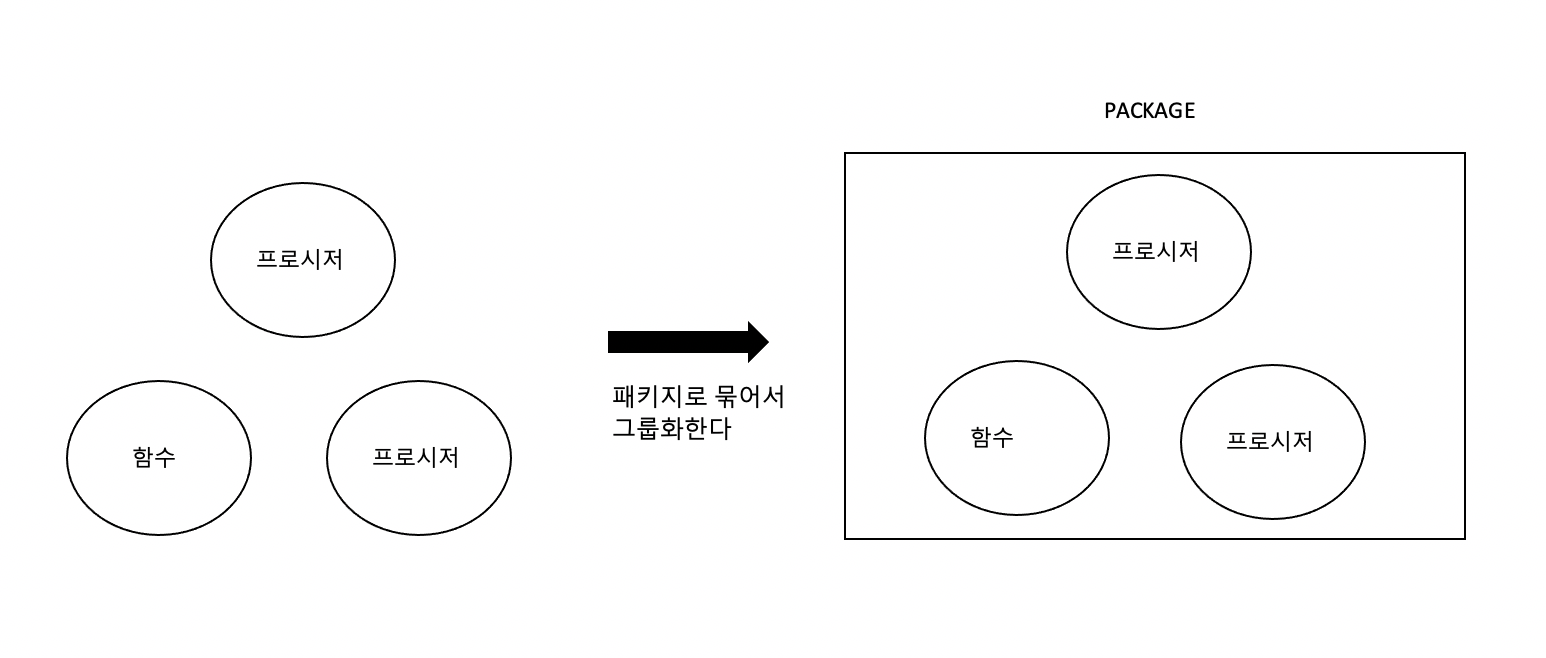
- 함수, 프로시저, 변수 등을 개념적으로 연결하여 그룹으로 만든 것이다.
- 프로시저나 함수와는 다르게 사양(specification)을 기술하는 부분과 본체(body)로 나누어 기술해야 한다.
- 캡슐화/비즈니스 로직을 감출 수 있다.
- 퍼포먼스 향상, 재사용성 높음
#Package Specification
PROCEDURE pro_a (a_para VARCHAR 2 );
PROCEDURE pro_b (b_para VARCHAR 2 ) ;
#Package Body
PROCEDURE pro_a (a_para VARCHAR2)
IS
no NUMBER;
...
PROCEDURE pro_b (b_para VARCHAR 2 ) ;
IS
val NUMBER;
...
트리거 (Trigger)
- 특정 이벤트가 발생했을때 자동으로 실행되는 스토어드 프로시저(Stored Procedure).
- enable 해두면 해당 이벤트가 발생했을 때 자동으로 실행, 명시적으로는 실행할 수 없음.
- Auditing이나 해당 이벤트에 연동하여 특정 처리를 하고 싶은 경우에 많이 쓰임.
PL/pgSQL 이해하기
여타의 RDBMS 벤더들이 DB서버 사이드에서 절차적 프로그래밍을 위한 언어로 오라클은 PL/SQL SQL Server는 Transact-SQL의 사용을 강제하는 데 반면 PostgreSQL에서는 가장 널리 쓰이는 SQL, PL/pgSQL뿐만 아니라 익스텐션 설치를 통해 PL/Perl, PL/Python, PL/Tcl 등도 지원한다.
Stored Procedure와 함수(function)의 차이
PRAGMA AUTONOMOUS_TRANSACTION를 사용하는 경우를 배제하면 함수는 일반적인 SQL 구문 속에서 사용이 가능하기 때문에 함수 내부에서 트랜잭션을 시작(start)하거나 완결(commit)할 수 없는 반면, 프로시저는 트랜잭션 컨트롤을 할 수 있어서 여러 개의 트랜잭션을 번갈아가며 실행할 수 있다. 프로시저는 SELECT 구문으로는 호출할 수 없고 CALL 구문을 이용하여 호출한다. 이 차이점에 유념할 필요가 있다. 함수는 PostgreSQL 초기 버전부터 존재한 기능인 반면 프로시저는 PostgreSQL 11 버전부터 지원한다. (EDB는 오라클 호환성 기능으로 9.x 버전부터 지원)
함수의 기본 형태
CREATE OR REPLACE FUNCTION mysum(int, int) RETURNS int AS
' SELECT $1 + $2; '
LANGUAGE 'sql';
함수의 본체(body)에 해당하는 부분은 작은 따옴표(')로 묶어주어야 하는 이는 문자열로 취급된다. 그리고 위 예제는 SQL로 작성되었으므로 LANGUAGE ‘sql’라고 정의해준다.
달러 기호로 문자열 묶기(dollar quoting)
작은 따옴표(')로 함수에 관한 코드를 문자열로 묶은 다음 PostgreSQL로 넘겨주는 과정에서 문제가 발생하는 경우가 있다. 문자열을 작은 따옴표로 묶는 것은 여러 프로그래밍 언어에서 많이들 써온 방식으로 보통은 이스케이핑 처리를 해서 넘기는데 PostgreSQL에서는 기호를 써서 정의할 수 있다.
CREATE OR REPLACE FUNCTION mysum(int, int) RETURNS int AS
$$
SELECT $1 + $2;
$$ LANGUAGE 'sql';
$$는 Perl이나 Bash에서 프로세스ID를 나타내는 일종의 예약어이기 때문에 아래 예제처럼 달러 기호 사이에 원하는 태그 값을 넣고 블록을 닫아주는 것으로 Perl이나 Bash에서 혹시라도 발생할 수 있는 에러를 방지할 수 있다.
CREATE OR REPLACE FUNCTION mysum(int, int) RETURNS int AS
$body$
SELECT $1 + $2;
$body$ LANGUAGE 'sql';
함수와 트랜잭션 사용하기
함수를 작성할 때에도 트랜잭션이 가장 기본 단위인 것에는 변함이 없다. 함수 또한 트랜잭션 안에서 동작하고(always part of the transaction) autonomous하지 않다.
edb=# SELECT now(), mysum(id, id) FROM generate_series(1, 3) AS id;
now | mysum
----------------------------------+-------
07-MAR-20 10:11:31.593846 +09:00 | 2
07-MAR-20 10:11:31.593846 +09:00 | 4
07-MAR-20 10:11:31.593846 +09:00 | 6
(3 rows)
edb=#
위 예제에서는 1부터 3까지의 범위에서 id라는 alias에 대입된 값이 mysum 함수의 파라미터로 넘어가고 이 함수가 3번 호출되는데 실행된 시간(now)을 통해서 같은 트랜잭션에서 실행되었음을 알 수 있다. 2번째 함수 호출에서 커밋되거나 하는 일은 있을 수 없다.
그러나 오라클에서 autonomous 트랜잭션을 허용하는 메커니즘을 도입했다. autonomous 트랜잭션의 기본 아이디어는 트랜잭션이 롤백되더라도 어떤 부분은 여전히 필요하기 때문에 유지되어야 한다는 것이다. 이에 관한 고전적인 예를 들어보면 아래와 같다.
- 중요한 데이터(secret data)를 조회하는 함수를 실행한다.
- 이 중요한 데이터에 변경이 발생했다면 그에 대한 로그 메시지를 작성한다.
- 로그 메시지를 커밋하고 데이터 변경분에 대해서는 롤백한다.
- 데이터 변경을 시도한 것에 관한 정보를 저장한다.
위와 같은 문제를 해결하기 위해서 autonomous 트랜잭션이 사용된다. 메인 트랜잭션 안에서 메인 트랜잭션과 독립적으로 트랜잭션을 커밋할 수 있다. 데이터 변경 분이 롤백되더라도 로그 메시지를 저장하는 트랜잭션은 영향을 받지 않는다. PostgreSQL에서는 아직 autonomous 트랜잭션이 지원되지 않지만(EDB에서는 가능) 조만간 지원될 것으로 보인다.
# autonomous 트랜잭션의 기본 형태
AS
$$
DECLARE PRAGMA AUTONOMOUS_TRANSACTION;
BEGIN
FOR i IN 0..9 LOOP
START TRANSACTION;
INSERT INTO test1 VALUES (i);
IF i % 2 = 0 THEN
COMMIT;
ELSE
ROLLBACK;
END IF;
END LOOP;
RETURN 42;
END;
$$;
PL/pgSQL 간략한 소개
Mastering PostgreSQL 11에 소개된 기능 위주로 살펴보면서 PL/pgSQL의 특징을 알아보자.
quoting 핸들링
데이터베이스 프로그래밍에서 가장 중요한 것 가운데 하나는 quoting일 것이다. 적절하게 quoting 처리를 하지 않으면 SQL injection이나 보안에 취약해질 수 있다.
CREATE FUNCTION broken(text) RETURNS void AS
$$
DECLARE
v_sql text;
BEGIN
v_sql := 'SELECT schemaname FROM pg_tables WHERE tablename = ''' || $1 || '''';
RAISE NOTICE 'v_sql: %', v_sql;
RETURN;
END;
$$ LANGUAGE 'plpgsql';
위 함수는 문자열 변수를 받은 다음 || 연산자를 통해서 앞뒤 문자열에 붙여주도록 하는 기능을 가진 평범한 함수이지만 SQL injection에 취약한 부분이 있다.
edb=# SELECT broken('t_test');
NOTICE: v_sql: SELECT schemaname FROM pg_tables WHERE tablename = 't_test'
broken
--------
(1 row)
edb=#
나쁜 의도를 가지고 아래와 같이 SQL injection 공격을 시도하는 경우를 생각해보자. 구문에는 문제가 없으므로 먼저 SELECT 구문이 실행되고 이어서 DROP table 구문이 실행될 수 있는 위험이 있다.
edb=# SELECT broken('''; DROP TABLE t_test; ');
NOTICE: v_sql: SELECT schemaname FROM pg_tables WHERE tablename = ''; DROP TABLE t_test; '
broken
--------
(1 row)
edb=#
위와 같은 SQL injection에 대비하기 위해 quote_ident(), quote_literal(), format() 같은 함수를 써서 문자열 타입으로 받아오는 파라미터에 대해 적절한 quoting 처리를 해야 한다. PostgreSQL 공식 문서의 Executing Dynamic Commands 항목을 참고한다.
scope 관리하기
다른 프로그래밍 언어들과 마찬가지로 PL/pgSQL에서 사용되는 변수도 컨텍스트에 따라 유효한 범위가 다르다. PL/pgSQL에서 변수는 DECLARE 선언 후 정의된다.
CREATE FUNCTION scope_test() RETURNS int AS
$$
DECLARE
i int := 7;
BEGIN
RAISE NOTICE 'i1: %', i;
DECLARE
i int;
BEGIN
RAISE NOTICE 'i2: %', i;
END;
RETURN i;
END;
$$ LANGUAGE 'plpgsql';
함수 실행 결과는 아래와 같다.
edb=# call scope_test() ;
NOTICE: i1: 7
NOTICE: i2: <NULL>
scope_test
------------
7
(1 row)
edb=#
에러 핸들링
모든 프로그래밍은 에러가 발생할 가능성이 있기 때문에 적절하면서도 효율적인 방식으로 에러를 처리하는 것이 중요하다. 여느 프로그래밍 언어들처럼 PL/pgSQL에서도 EXCEPTION 블록을 사용하여 에러를 핸들링 할 수 있다. BEGIN 블록 내에서 문제가 발생하였을 때 그 문제를 캐치하여 적절하게 처리하는 것이 핵심 내용이다. 아래의 예제 함수는 division by zero 에러가 발생하면 그 에러를 캐치하여 적절하게 핸들링한다.
CREATE FUNCTION error_test(int, int) RETURNS int AS
$$
BEGIN
RAISE NOTICE 'debug message: % / %', $1, $2;
BEGIN
RETURN $1 / $2;
EXCEPTION
WHEN division_by_zero THEN RAISE NOTICE 'division by zero detected: %', sqlerrm;
WHEN others THEN RAISE NOTICE 'some other error: %', sqlerrm;
END;
RAISE NOTICE 'all errors handled';
RETURN 0;
END;
$$ LANGUAGE 'plpgsql';
EXCEPTION 블록에서 sqlerrm 변수에 담긴 에러 내용을 보여줌으로써 문제를 찾아 디버깅하기가 수월해진다. 사용자가 자신만의 exception을 정의하여 사용할 수도 있다. PostgreSQL에서는 사전에 정의된 다양한 에러 코드와 exception을 제공하니 이 곳을 참고하여 관련 내용을 확인하자.
Porting from Oracle PL/SQL
오라클 PL/SQL 구문의 기본 개념을 이해한 상태에서 Migration from Oracle to EDB/PostgreSQL을 수행하는 데 참고가 될 만한 내용들을 정리한다. 먼저 오라클과 EDB, PostgreSQL 간에 호환 가능한 주요 데이터 타입을 확인한다. PostgreSQL의 경우에는 이 글을 참고하여 대체 가능한 데이터 타입을 포함시켰다.
- Data Type Conversion
| Oracle | EDB v10 | EDB v11 | EDB v12 | PostgreSQL |
|---|---|---|---|---|
| VARCHAR2 | VARCHAR2 | VARCHAR2 | VARCHAR2 | varchar (or char, text, json) |
| DATE | DATE | DATE | DATE | date |
| LONG | LONG | LONG | LONG | char, varchar, text |
| CLOB | CLOB | CLOB | CLOB | char, varchar, text, json |
| BLOB | BLOB | BLOB | BLOB | bytea |
| NCLOB | ✖︎ | ✖︎ | ✖︎ | ✖︎ |
| RAW | RAW | RAW | RAW | uuid, bytea |
| ROWID | ROWID | ROWID | ROWID | ctid (not the same) |
| FLOAT | FLOAT | FLOAT | FLOAT | numeric, float4, float8 |
| DEC | DEC | DEC | DEC | dec |
| DECIMAL | DECIMAL | DECIMAL | DECIMAL | decimal |
| INT | INT | INT | INT | integer |
| INTEGER | INTEGER | INTEGER | INTEGER | integer |
| NUMBER | NUMBER | NUMBER | NUMBER | numeric |
| TIMESTAMP | TIMESTAMP | TIMESTAMP | TIMESTAMP | timestamp |
| PLS_INTEGER | PLS_INTEGER | PLS_INTEGER | PLS_INTEGER | ✖︎ |
| TIMESTAMP WITH TIME ZONE | TIMESTAMP WITH TIME ZONE | TIMESTAMP WITH TIME ZONE | TIMESTAMP WITH TIME ZONE | timestamptz |
읽어두면 좋을 레퍼런스
EDB 사에서는 개발자를 위한 버전별 오라클 호환성 기능에 관한 가이드 문서를 별도로 제공하고 있기 때문에 참고하면 좋다.
- EDB v10 Database Compatibility for Oracle®
- EDB v11 Database Compatibility for Oracle®
- EDB v12 Database Compatibility for Oracle®
- PG 개발그룹에서 작성한 PL/pgSQL 명세서도 주의 깊게 읽어둘 필요가 있다.
- Perl로 작성된 ora2pg 툴에 관한 문서에서 PLSQL to PLPGSQL conversion도 참고한다.