pg_rman을 통해 이해하는 PG의 백업과 복구
Overview
2009년 12월부터 개발이 시작되어 이 글을 쓰고 있는 시점(2019년 12월)에도 유지•보수가 이어지고 있는 백업 솔루션이다. DB업계에서 사실상의 표준(de facto standard) 지위를 누리고 있는 오라클DBMS의 RMAN과 유사한 인터페이스를 제공함으로써 오라클DBMS를 중심으로 경력을 이어왔고 이제 막 PG로 진입한 DBA가 백업과 복구에 관한 문제에 직면하였을 때 그 솔루션으로 대안이 될 수 있다.
C언어로 작성되었기에 github 저장소에서 소스(raw source file)를 내려받아서 설치하려면 컴파일이 필요하다. 레드햇 패밀리 계열 리눅스 OS 플랫폼을 대상으로는 PG 버전별로 패키지 파일을 제공하기에 직접 컴파일하여 설치하는 것보다는 자신의 환경에 맞는 패키지 파일을 받아서 설치하는 편을 추천한다. 디폴트 설치 경로는 PG의 각종 유틸리티가 존재하는 /usr/pgsql-1/bin이다. 따라서 pg_rman을 edb에 도입한다면 /usr/edb/as1/bin로 pg_rman을 옮겨둘 필요가 있다.
유사한 기능을 제공하는 백업&복구 솔루션으로 EDB에서 제공하는 것으로는 BART, 오픈소스 방식으로 2ndQuadrant에서 유지•보수하는 BARMAN이 있다. 근간이 되는 백업&복구의 기본개념은 닮아 있다. 그 외에도 OmniPITR, PgBackRest, PgHoard, WAL-E 등이 있는데 WAL-E는 최근 2~3년 동안 maintaining이 이뤄지지 않고 있다.
백업 솔루션의 구체적인 사용법을 익히기 전에 DML 트랜잭션이 발생하면 그 내용(커밋 내용, 인덱스 포인트 정보, 체크섬 등을 포함한 해당 오퍼레이션의 다양한 정보)이 처리되는 과정을 복습하고 checkpoint, timeline 같은 개념을 되새본 뒤에 pg_rman 사용법을 익히는 과정으로 나아가자.
새로운 데이터가 insert 되는 상황에서 일어나는 일들
edb=# BEGIN;
edb=# INSERT INTO TABLE_A (col1, col2) VALUES ('1', '2');
edb=# COMMIT;
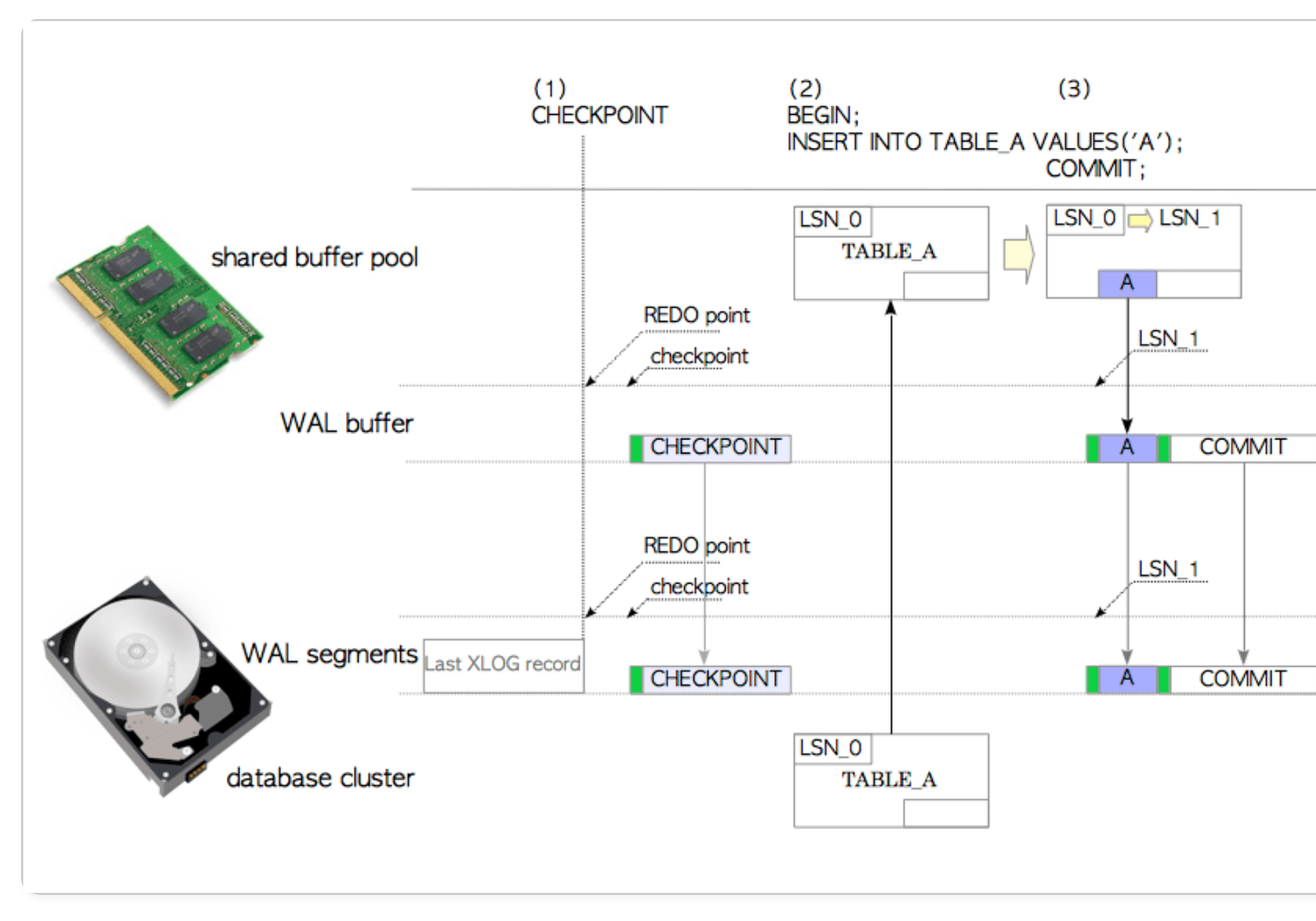
Image from The Internals of PostgreSQL Chapter 9
- PG는 장애에 대비해 모든 변경내용의 이력 정보를 영속적인 스토리지 영역에 저장하는데 이런 변경내용의 이력 정보를 저장하고 있는 데이터를 WAL(a.k.a XLOG 레코드)이라고 한다.
- 테이블에 DML 작업을 하는 워크로드일 경우, 변경이 일어날 테이블의 페이지(page)가 메모리 상에 존재하지 않으면 해당 테이블 파일을 찾아서 Shared Buffer 메모리 상에 적재(Load)한다.
- DML 트랜잭션 로그는 WAL 버퍼라는 메모리 상에 존재하다가 commit 또는 abort되는 즉시 스토리지 상의 WAL 세그먼트 파일에 저장된다(Write and Flush).
- commit 또는 abort로 트랜잭션이 종결되면 LSN(Log Sequence Number)이 증가한다.
- DML 트랜잭션이 종료되면 변경내용은 일단 메모리 상의 page에 저장된다. 즉 변경내용이 해당 테이블 데이터가 속한 스토리지 내의 파일에 바로 반영되는 것은 아니다.
CHECKPOINT
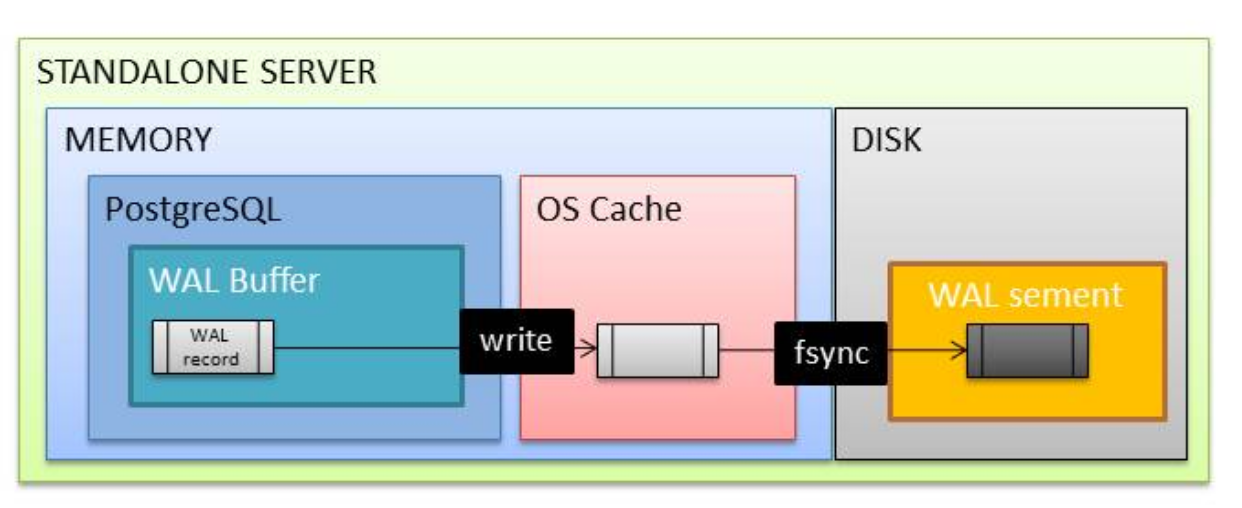
Image from PostgreSQL synchronous_commit 개념도
CHECKPOINT의 기본 동작
- 먼저 shared buffer에 저장된 변경이 발생한 모든 페이지(dirty pages)을 식별한다(identify).
- 버퍼(메모리)에 저장돼 있는 변경 블록을 디스크에 쓴다(flush).
- 버퍼에 저장된 데이터(메타데이터 + 데이터)가 물리적인 디스크에 쓰였음을 보장하는 fsync 시스템 콜 호출을 통해 버퍼 캐시의 내용과 디스크의 파일 시스템을 동기화한다.
checkpoint와 관련된 주요 파라미터
- checkpoint_timeout(디폴트 5min, 설정 가능한 값의 범위는 30s - 1d)
- min_wal_size, max_wal_size(max 사이즈에 도달하면 wal 새그먼트 파일(16진수 24자릿수로 된 디폴트 16MB의 파일, v12부터 initdb 단계에서 –wal-segsize 값을 MB단위로 지정하여 변경이 가능해짐)을 rename 후 재사용해야 하기 때문에 checkpoint를 발생시켜서 메모리 상의 변경내용을 영속적인 스토리지에 쓴다)
- checkpoint_completion_target
- log_checkpoints(로그에 checkpoint 발생 관련 로그를 기록하도록 한다)
CHECKPOINT가 발생하는 상황
- 사용자가 직접 checkpoint 명령어를 수행하거나 설정된 주기 및 특정 조건을 만족했을 때 checkpoint가 발생한다.
-
pg_start_backup, pg_basebackup, CREATE DATABASE 구문 또는 pg_ctl stop restart 수행할 시에도 checkpoint가 발생한다. - checkpointer와 background writer라는 이름의 두 가지 프로세스가 checkpoint와 관계된 백그라운드 프로세스다.
checkpoint_timeout의 텀은 어떻게 설정하는 것이 적절한가.
9.6 이전 버전까지는 퍼포먼스 관점에서 checkpoint_timeout의 텀을 짧게 설정하는 것을 권고하는 경향이 있었는데 그 이후 버전부터는 DB 내부의 최적화 로직이 개선되고 OS 레벨에서의 속도 개선도 더해져서 과거보다 텀을 길게 설정하는 것을 권고하고 있다. Mastering PostgreSQL 11의 저자이자 Cybertec이라는 PG 벤더사의 CEO인 Hans-Jurgen Schonig 씨에 따르면 9.6 버전 이후부터는 기본적으로 checkpoint 발생 텀을 길게 가져가는 것(30min)이 바람직하다고 주장한다. checkpoint 텀이 길수록 full-page writes가 덜 발생하고 그렇다는 것은 WAL 발생이 준다는 것을 의미하기 때문에 I/O 퍼포먼스 관점에서 좋다는 주장이다.
예를 들어 shared_buffers용으로 메모리 100GB를 할당했고 쓰기 작업이 빈번한 시스템이 있다고 하자. 이런 시스템에서 checkpoint 발생 조건이 충족되었을 때 쓰기 작업으로 메모리 상에 쌓인 100GB분의 변경내역을 한번에 디스크로 쓰려는 상황이 있을 수 있다. 메모리 상의 dirty pages를 디스크로 flush하는 작업은 대량의 I/O 작업을 동반하기 때문에 커다란 부하를 발생시키고 일상적인 쿼리(normal query)에 응답하는 처리를 하는 데 나쁜 영향을 주게 된다. 이런 상황에서 조정을 검토해봄직한 파라미터가 checkpoint_completion_target이다.
이 파라미터는 checkpoint_completion_target와 checkpoint_timeout의 값을 곱한 시간 동안 좀더 천천히 데이터를 쓰도록 시도한다. checkpoint_timeout(5min)와 checkpoint_completion_target(0.5) 값이 디폴트 값 그대로 설정돼 있다면 그 둘을 곱한 값은 2.5분(2분 30초)이고 이 값이 의미하는 바는 PostgreSQL 엔진에게 2.5분에 걸쳐 checkpoint 작업을 진행하라는 것이다.
예로 든 시스템으로 돌아와서 디스크에 써야 할 메모리 상의 변경내역이 100GB이고 디스크의 최대 쓰기 속도가 초당 1GB라고 해보자. 최대 쓰기 속도로 메모리 상의 변경내역 100GB을 디스크에 쓴다면 100초(1분 40초)가 걸릴 것이다. checkpoint_timeout가 5min이고 checkpoint_completion_target 값이 0.5라고 한다면 2분 30초 동안 쓰기 작업을 완료하면 되기 때문에 1GB/1s 최대 속도가 아니어도 700MB/1s 정도의 쓰기 속도이면 2분 30초 안에 쓰기 작업을 마칠 수 있고 그렇게 아낀 30% 정도의 쓰기 자원은 다른 목적을 위해 쓸 수 있다.
checkpoint_completion_target 설정에 따른 디스크 I/O 변화를 테스트한 글을 참조하면서 이해를 더해가보자. 아래 조건에서 테스트가 진행됐다.
pgbench 스케일 팩터 값은 15였고 생성된 데이터의 크기는 약 300MB.
- shared_buffers = 1024MB
- log_checkpoints = on
- checkpoint_segments = 30 (deprecated and replaced by max_wal_value since v9.5)
- checkpoint_timeout = 5min
- checkpoint_warning = 5min (체크포인트가 설정된 시간 이상 진행되면 경고 로그를 남긴다)
- log_line_prefix = ‘%m %r %u %d %p’
- log_min_duration_statement = 5
checkpoint_completion_target = 0으로 설정했을 때의 %util 변화
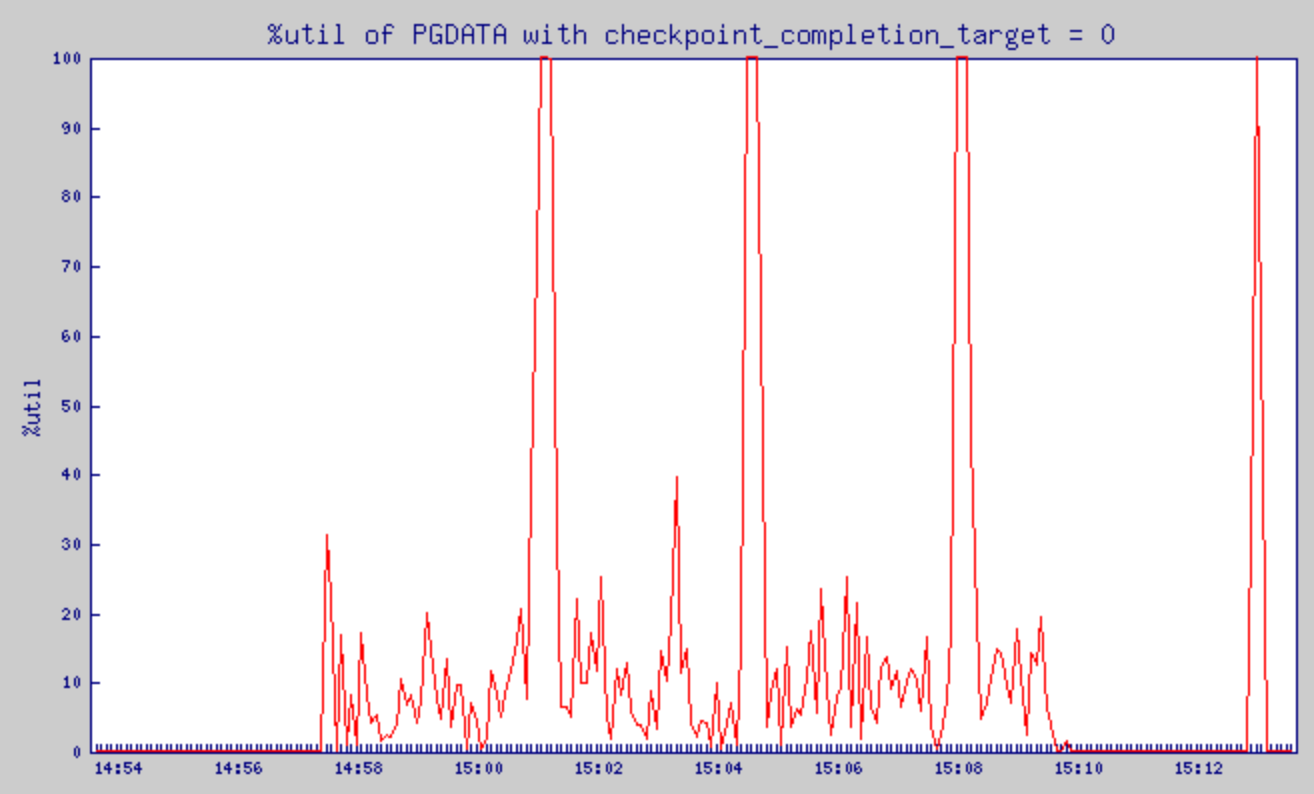
- Pgbench 가동 시간대 14:57:34 ~ 15:09:34
- %util은 디스크 read/write시의 CPU사용률
checkpoint_completion_target = 0으로 설정했을 때의 await 변화
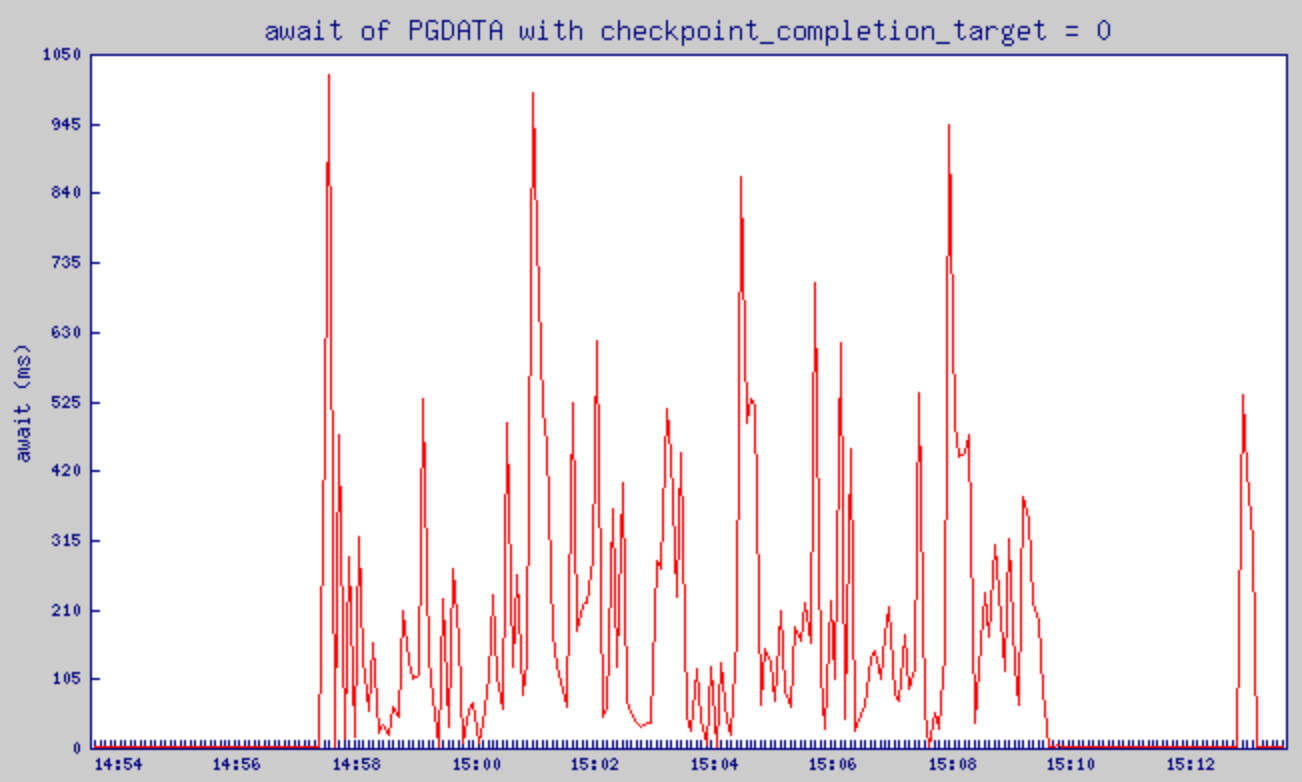
- await는 해당 Device에 발생된 I/O request의 평균 서비스 타임(단위 ms). queue 대기시간과 서비스 시간을 포함한다.
checkpoint_completion_target = 0.3으로 설정했을 때의 %util 변화
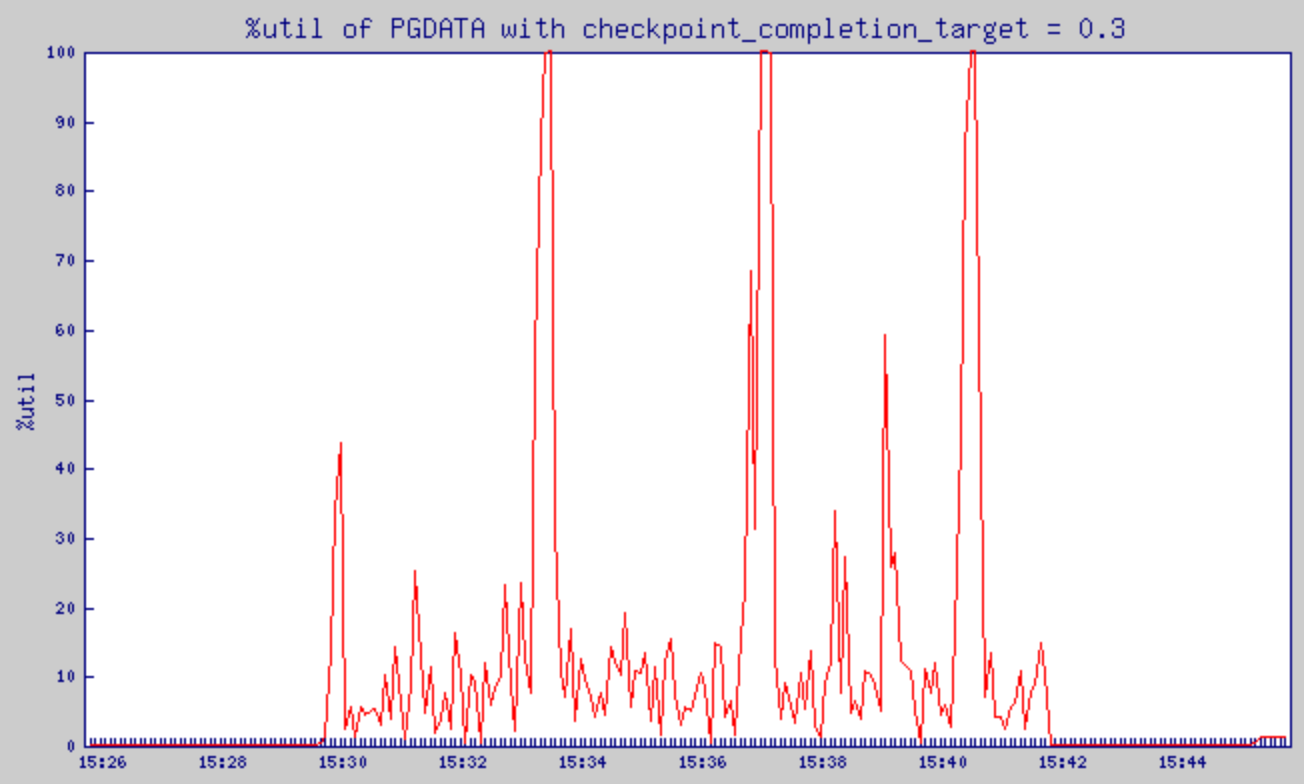
- Pgbench 가동 시간대 14:57:34 ~ 15:09:34
checkpoint_completion_target = 0.3으로 설정했을 때의 await 변화
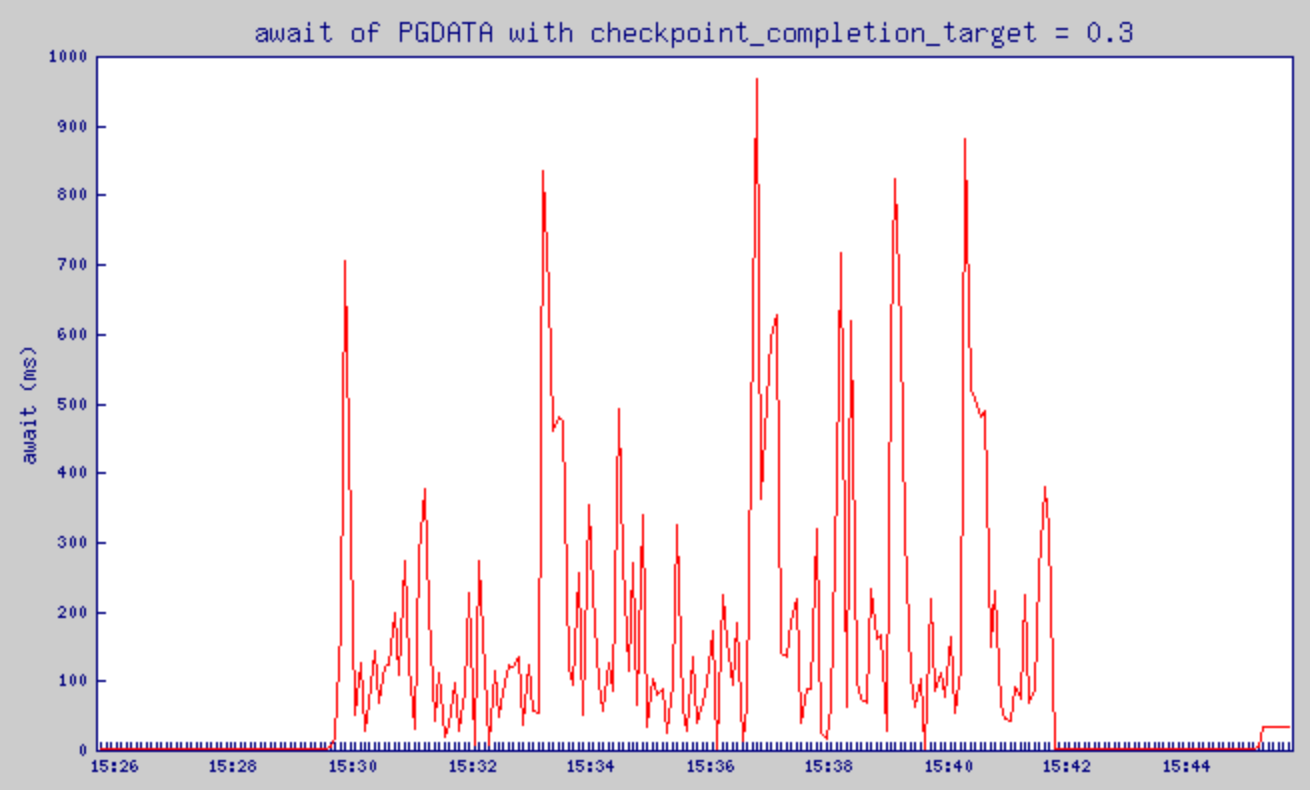
- Pgbench 가동 시간대 14:57:34 ~ 15:09:34
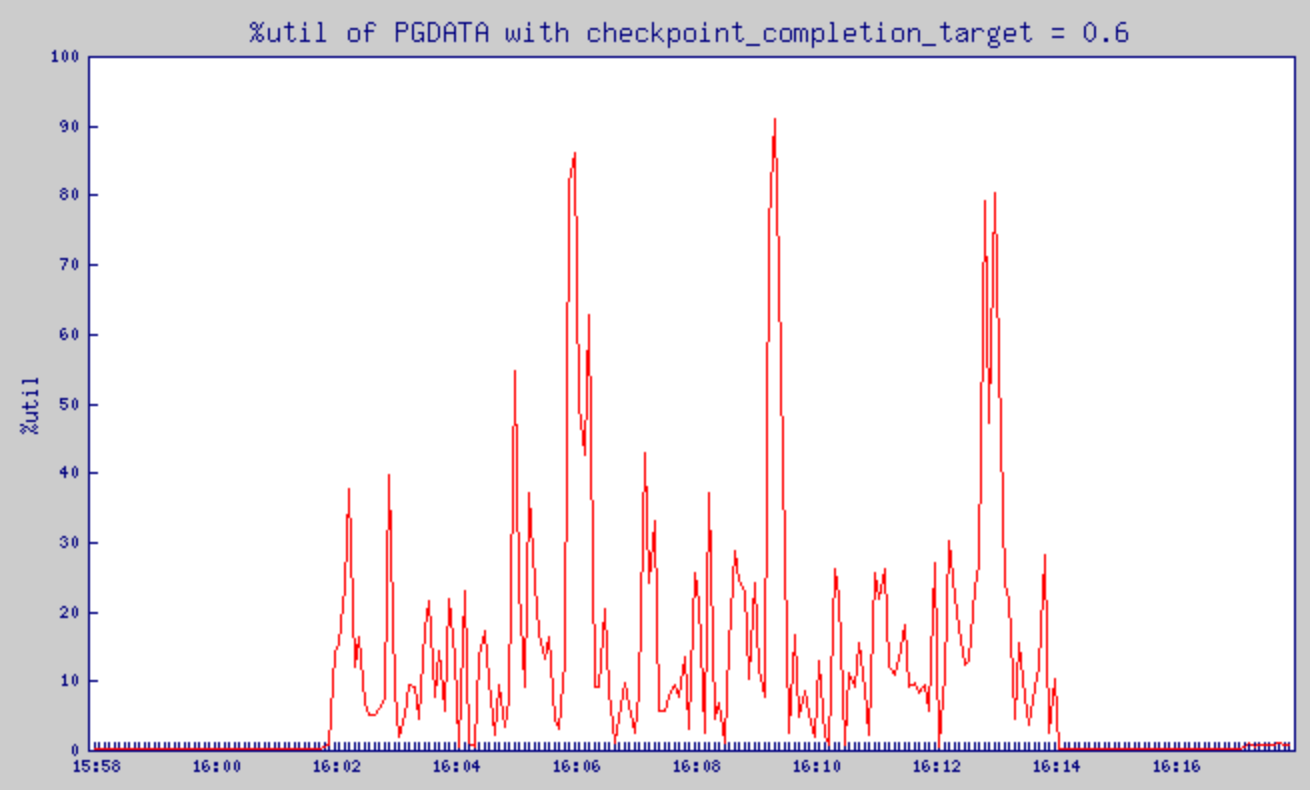
checkpoint_completion_target = 0.6으로 설정했을 때의 %util 변화
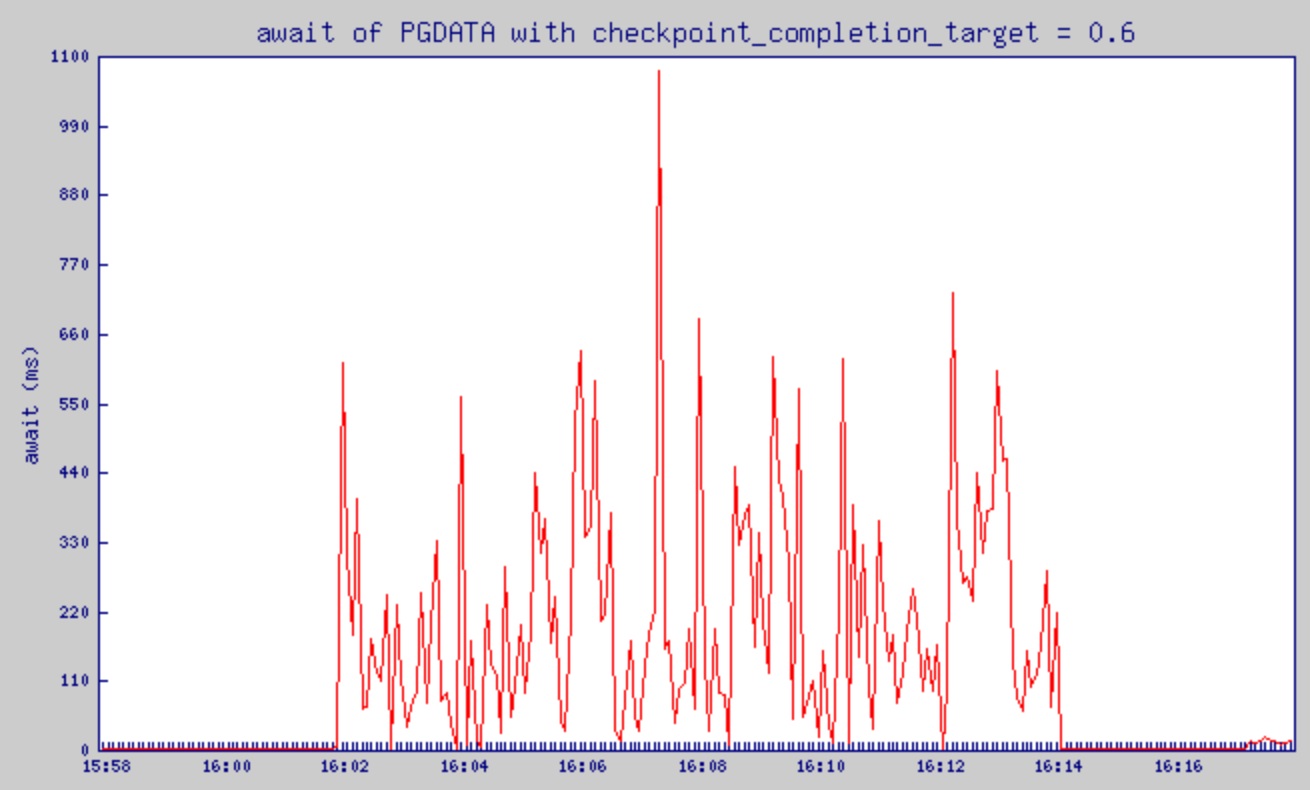
checkpoint_completion_target = 0.6으로 설정했을 때의 await 변화
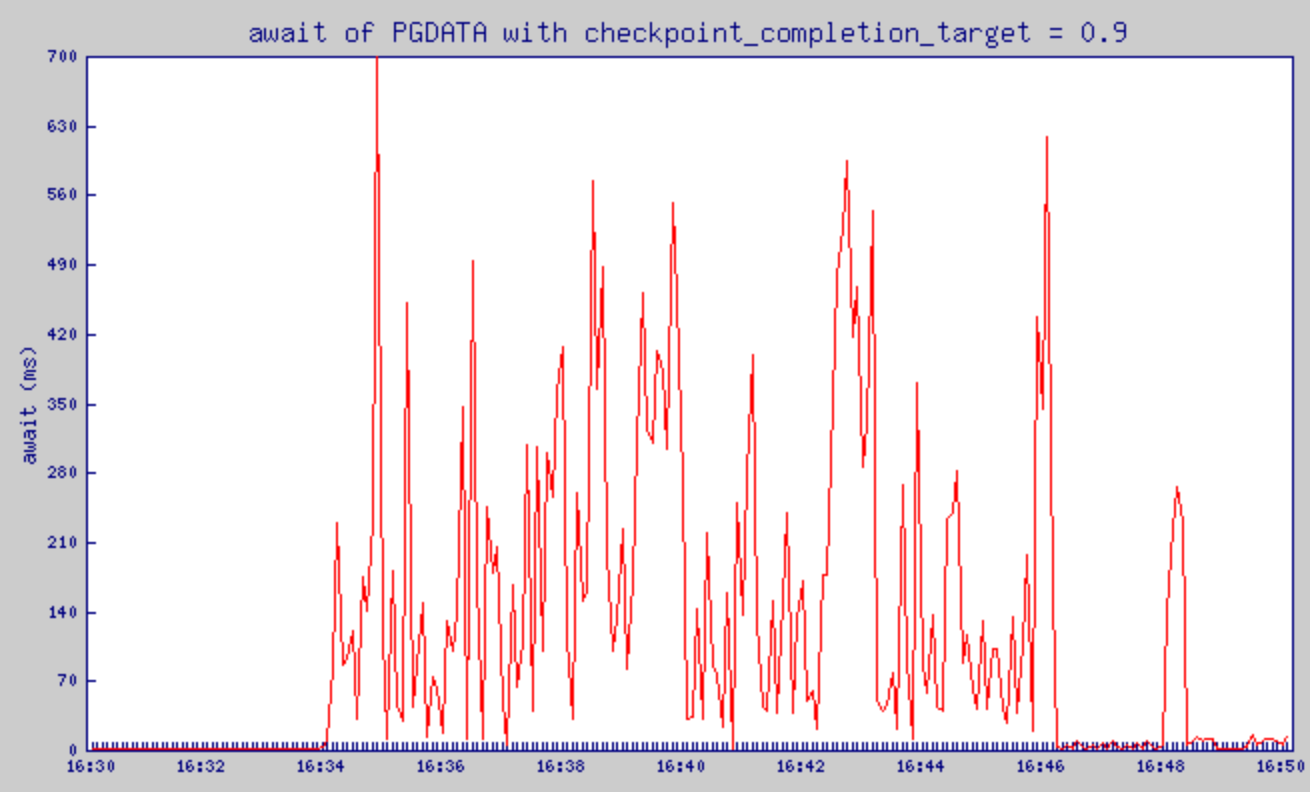
checkpoint_completion_target = 0.9으로 설정했을 때의 %util 변화
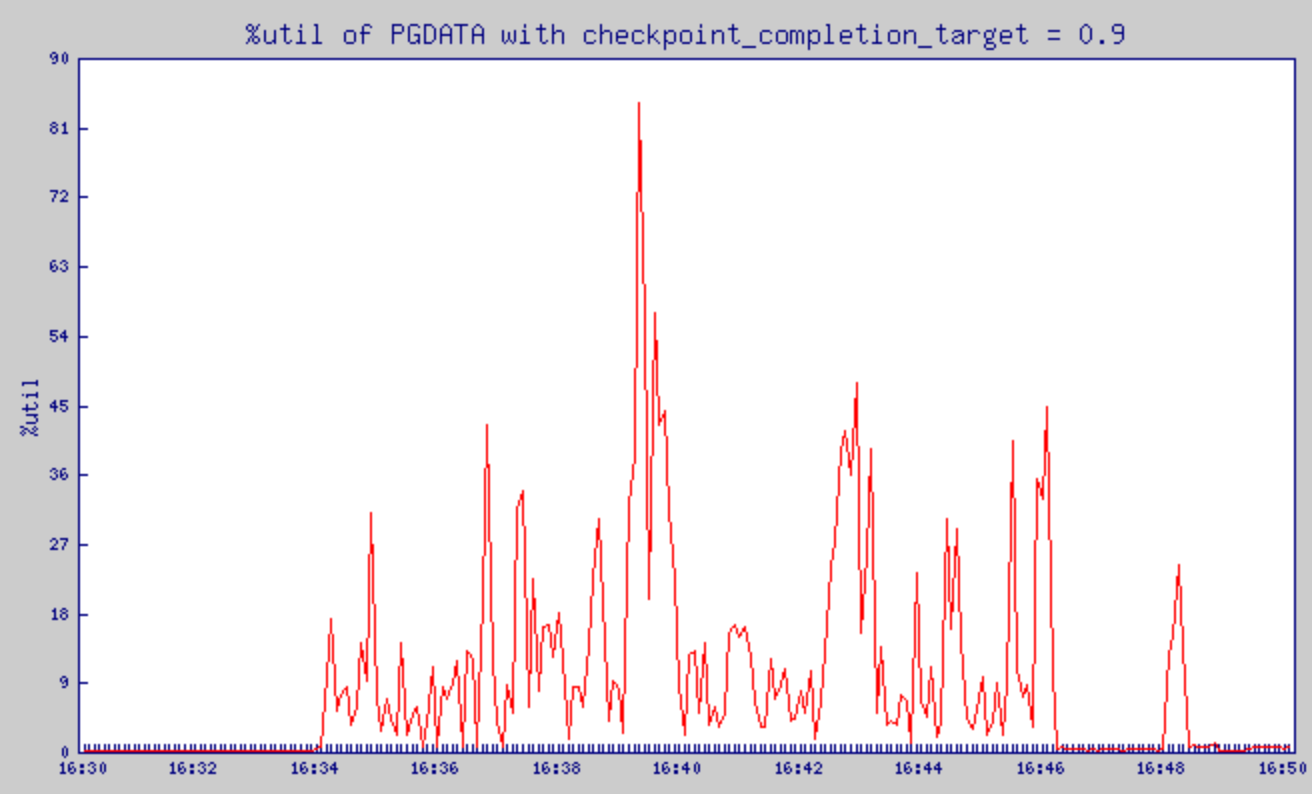
checkpoint_completion_target = 0.9으로 설정했을 때의 await 변화
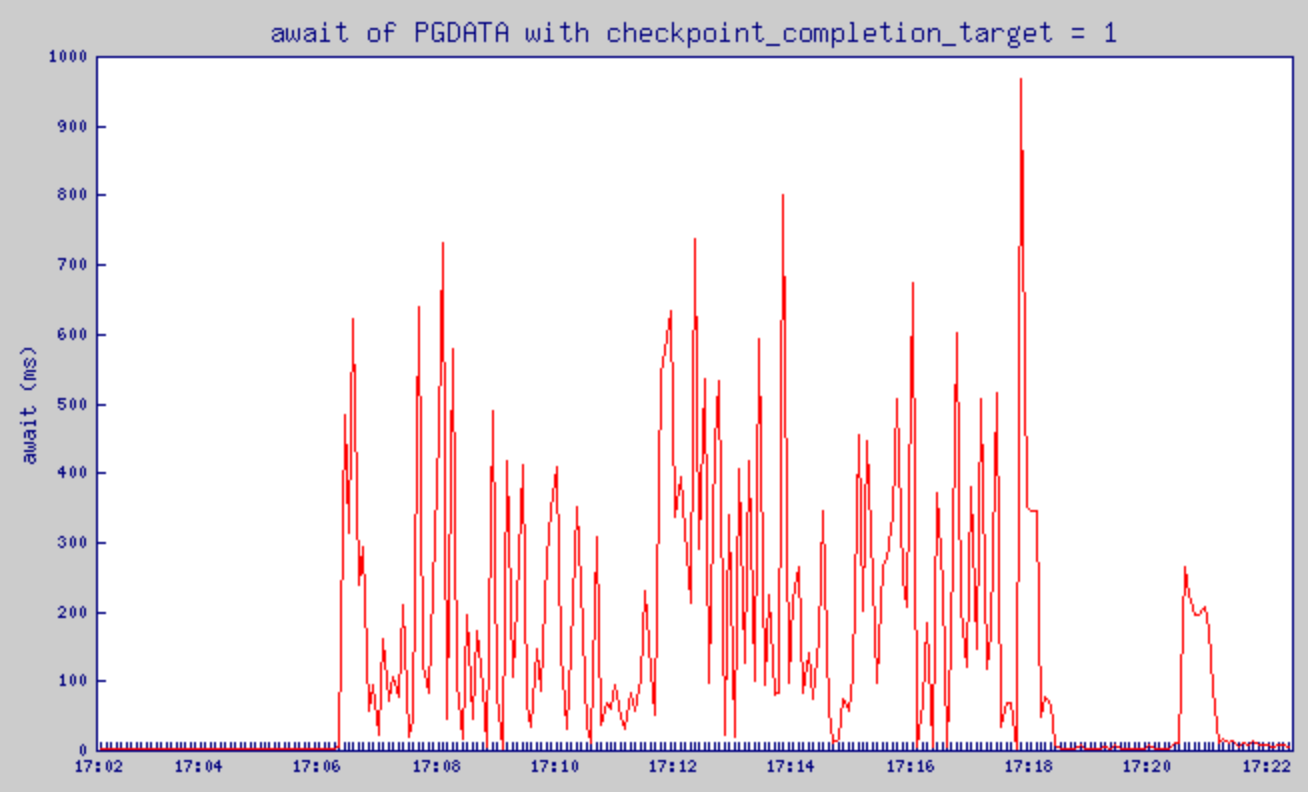
checkpoint_completion_target = 1로 설정했을 때의 %util 변화
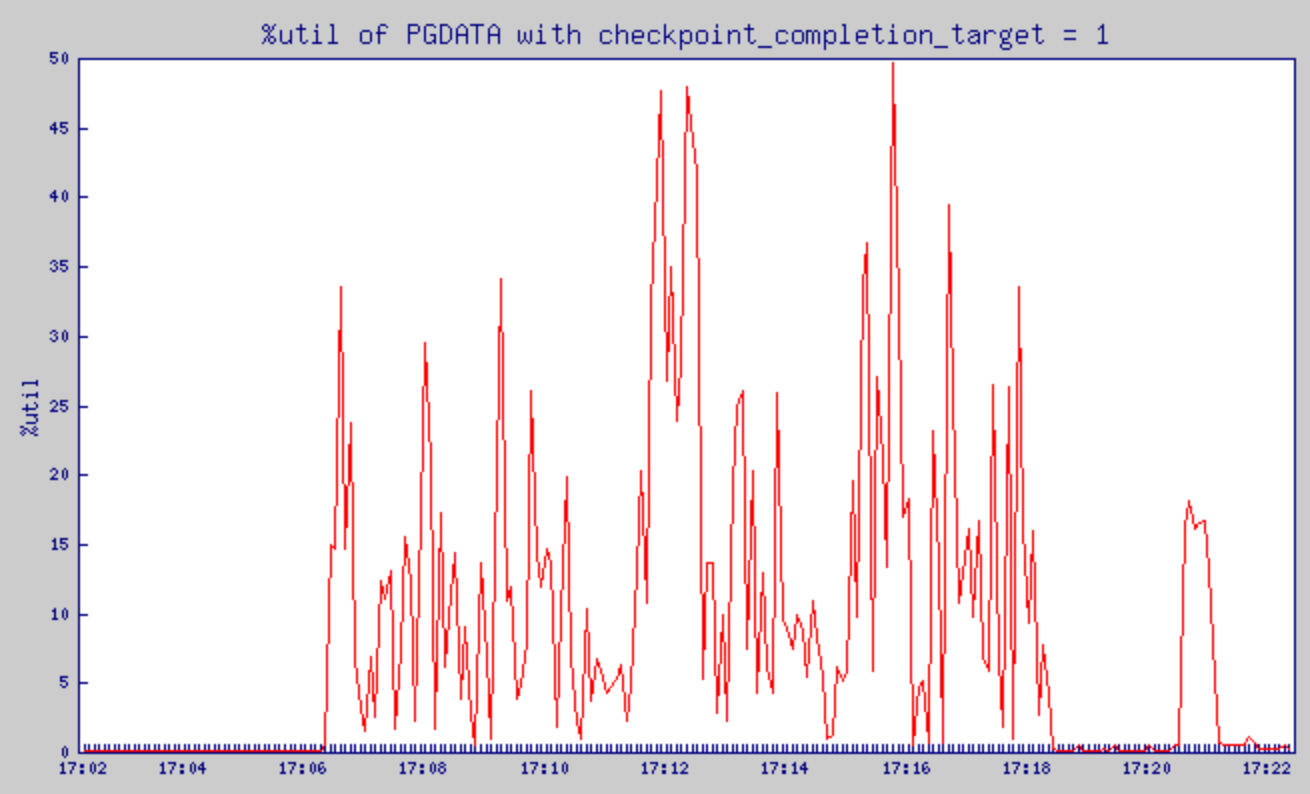
checkpoint_completion_target = 1로 설정했을 때의 await 변화
checkpoint_completion_target 설정 값에 따른 slow 쿼리 수의 변화
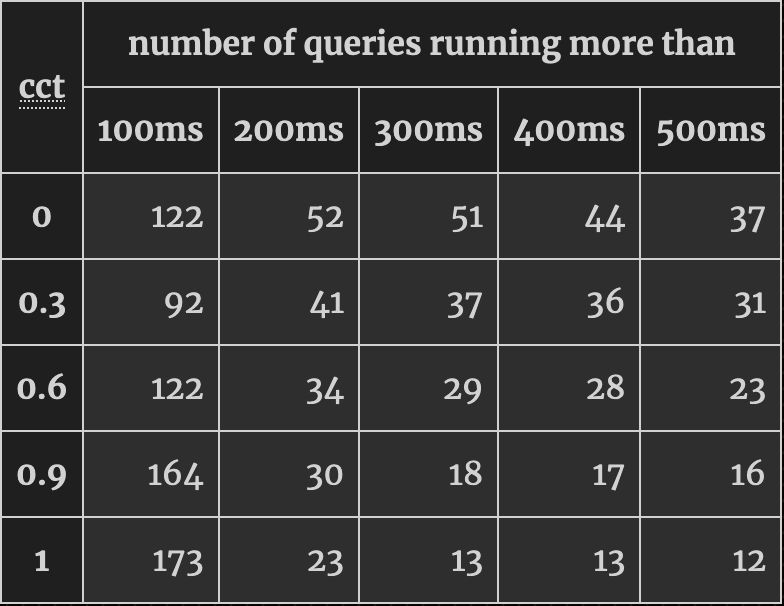
100ms - 200ms 범위에서는 꼭 그렇다고 할 수 없지만 checkpoint_completion_target(이하 줄여서 cct) 값이 1에 가까워질수록 200ms 이상 걸리는 쿼리의 수가 줄어드는 것을 확인할 수 있다.
cct 값을 크게 할수록 좋기만 한 것일까. 단점(drawback)은 무엇일까?
- wal 새그먼트를 저장하는 pg_wal(v10 이전에는 pg_xlog)가 비대해질 수 있다.
- 항상 기대한대로 동작하는 것은 아니다. share_buffers의 크기가 매우 크고 쓰기 작업이 많은 시스템에서는 아래 그림처럼 체크포인트가 거의 항시 발생한다.
- 체크포인트 텀이 길어질수록 강제로 종료된 상황이나 재기동 시에 수행되는 리커버리 과정에 시간이 더 오래 걸릴 수 있음(REDOPOINT가 뒤에 있기 때문)을 인지하고 있어야 한다.
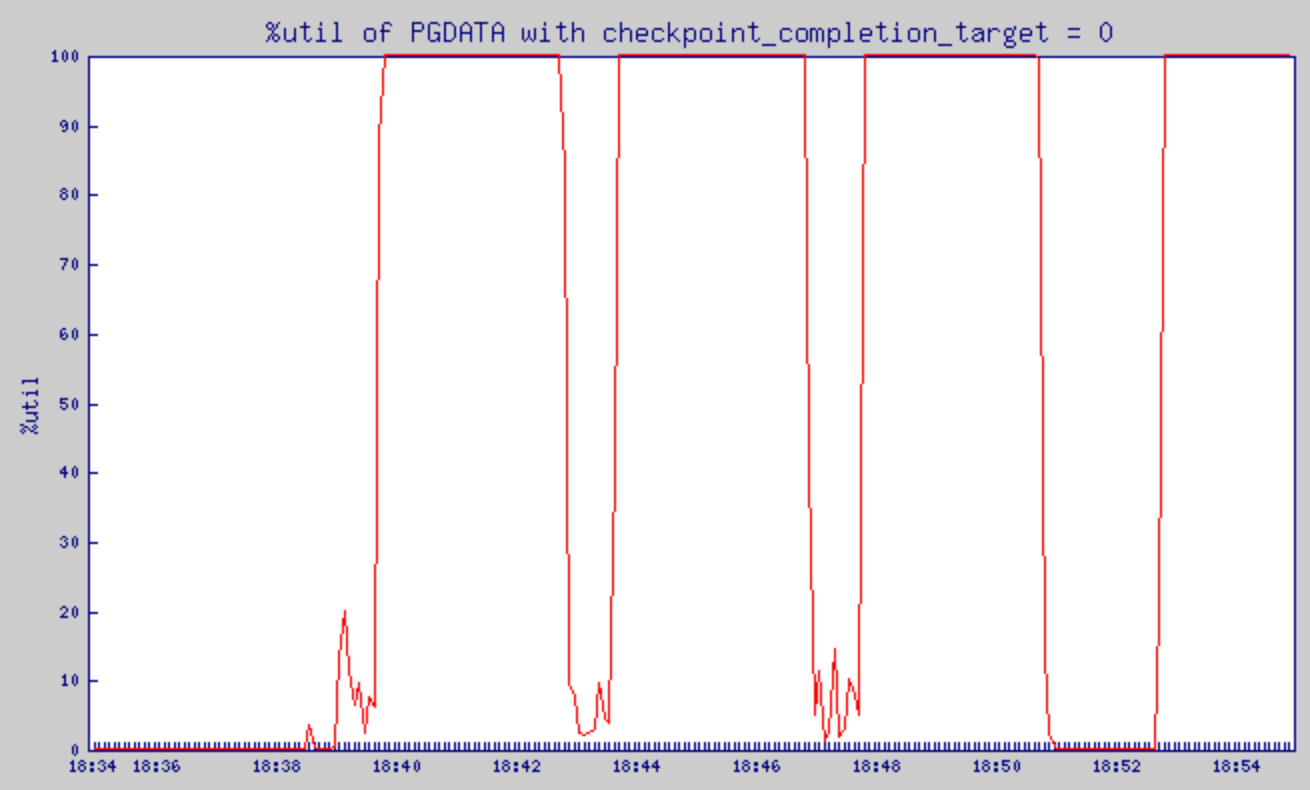
pgbench 스케일 팩터 값으로 35를 주었을 때의 결과 그래프. (순간적으로 550MB 가량의 데이터 발생)
Base Backup
logical backup
- pg_dump & pg_restore
- 데이터베이스가 클수록 시간이 오래 걸린다.
physical backup
- logical backup과 비교해서 데이터베이스를 백업하고 복원하는 데 걸리는 시간이 상대적으로 짧다.
| SQL dump to an archive file: pg_dump -F c | SQL dump to a script file: pg_dump -F p or pg_dumpall | Filesystem backup using: pg_start_backup | |
|---|---|---|---|
| 백업 타입 | Logical | Logical | Physical |
| PITR | 불가 | 불가 | 가능 |
| Zero data loss | No | No | Yes |
| 모든 DB 백업 | 한번에 하나씩 | pg_dumpall 사용시 가능 | 가능 |
| DB를 선택해 백업 | 가능 | 가능 | 불가 |
| 증분(Incremental) 백업 | 불가 | 불가 | 가능1 |
| 백업 파일 압축 | 가능 | 가능 | 가능 |
| 백업 파일 여러 개로 분할 | 불가 | 불가 | 가능 |
| 병렬 백업 | 불가 | 불가 | 가능 |
| 병렬 복구 | 가능 | 불가 | 가능 |
| 백업 중에 DDL 허용 | 불가 | 불가 | 가능 |
quoted from PostgreSQL 10 Administration CookBook
pg_start_backup
- 강제로 full-page write 모드로 전환시킨다.
- 현재의 WAL 새그먼터 파일을 스위치한다.
- checkpoint를 실행한다.
- base directory 최상단 path에 backup_label를 생성한다.
backup_label 파일에 담기는 정보
- CHECKPOINT LOCATION : pg_start_backup를 실행했을 때 발생한 체크포인트가 기록된 LSN 위치.
- START WAL LOCATION : PITR시에 사용되는 값은 아니고 SR시에 사용된다.
- BACKUP METHOD : 백업 방식에 대한 설명. pg_start_backup 또는 pg_basebackup 값을 갖는다.
- BACKUP FROM : 백업이 primary와 standby 중에 어디에서 발생했는지 기록한다.
- START TIME : pg_start_backup가 실행된 시간.
- LABEL : pg_start_backup 실행시 입력한 라벨 값.
- START TIMELINE : v11부터 도입되었고 백업 시작 시점의 타임라인 값을 기록한다.
- 해당 LSN 정보로 관련 WAL 파일을 찾는 API select pg_walfile_name(‘LSN 넘버’);
pg_stop_backup
- pg_start_backup 시점에 강제로 full-page write 모드로 변경되었다면 이를 non-full-page write로 재설정한다.
- backup이 끝남을 알리는 XLOG를 쓴다.
- WAL 새그먼트 파일을 스위치한다.
- 백업 히스토리 파일 생성.
- backup_label 파일 삭제.
pg_basebackup 유틸리티
- 가장 간단하게 base backup을 만들 수 있는 방법.
- 내부적으로 pg_start_backup, pg_stop_backup 같은 로우 레벨(low-level) 명령어가 실행된다.
pg_basebackup 사용을 위해 적절히 설정되어야 할 파라미터들
- wal_level = replica or hot_standby(v10 이전)
- max_wal_senders = 10 (최소 2)
- archive_mode = on
- archive_command
- pg_hba.conf의 replication (REPLICATION 권한을 가진 유저에 대한 접속을 허용)
pg_basebackup 유틸리티를 이용한 간단한 백업 예제
pg_basebackup -h 172.17.0.2 -D /archive/arc_wal/data --checkpoint=fast --wal-method=stream -v -R
pg_basebackup -Ft -X none -D - | gzip > /archive/arc_wal/data/db_backup_$(date +%Y%m%d%H%M%S).tar.gz
pg_ctl stop -D $PGDATA
rm -rf $PGDATA/*
ls -al $PGDATA
tar xvfz /archive/arc_wal/data/db_backup_*.tar.gz -C /var/lib/edb/as11/data
vi recovery.conf
recovery_target_time (if necessary)
restore_command = 'cp /archive/arc_wal/%f %p'
watch -n 0.5 ls -alth

Magnus Hagander 씨의 PostgreSQL Backups the modern ways 발표 참고.
timeline 그리고 timelineID, Timeline History 파일
오리지널 데이터베이스와 그로부터 복원된 데이터베이스를 구분하려는 개념이다. PITR에서 핵심이 되는 개념으로 timelineID와 Timeline History 파일로 구성돼 있다.
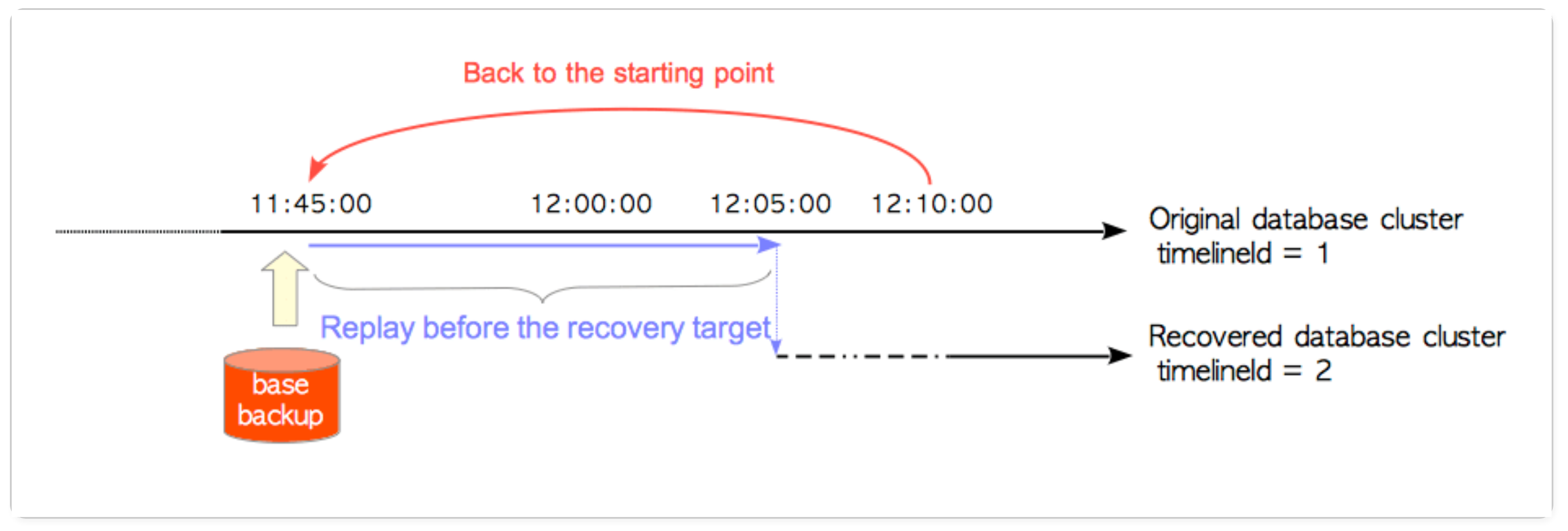
Image from The Internals of PostgreSQL Chapter 10
WAL 새그먼트 파일
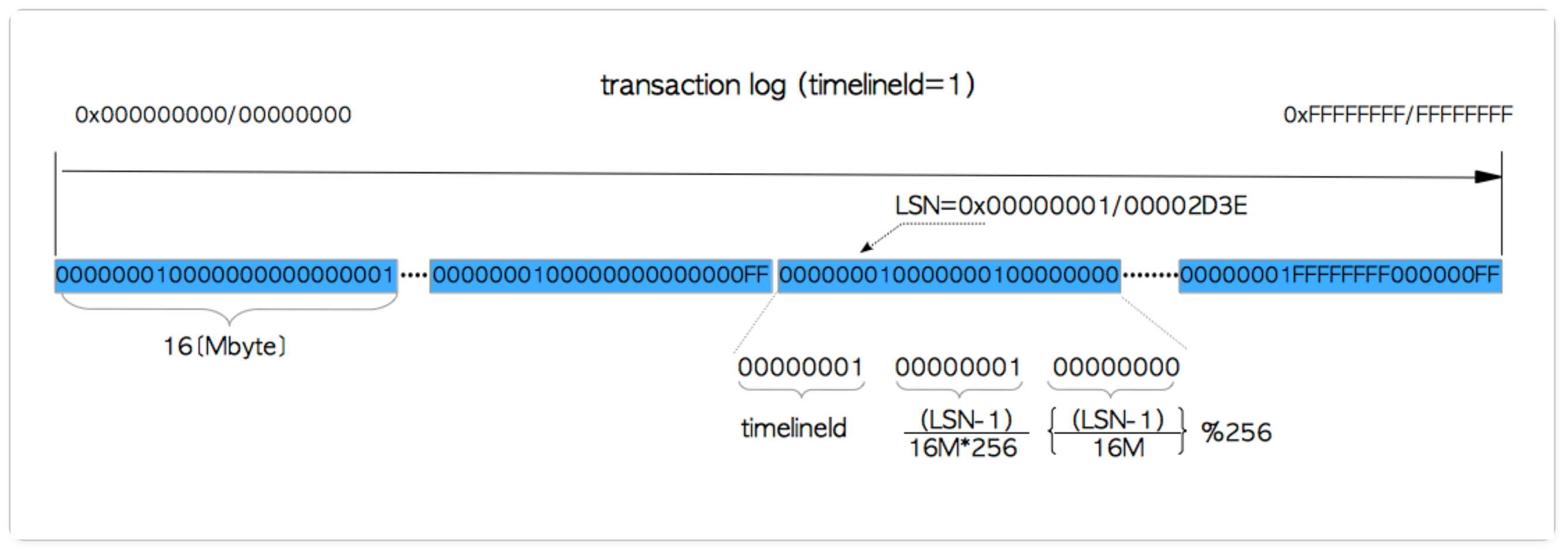
Image from The Internals of PostgreSQL Chapter 9
WAL 새그먼트 파일명에서 첫 8자리는 타임라인ID 값을 의미한다. 복원된 데이터베이스 클러스터에는 1이 증가한 타임라인ID 값이 배정되고 그에 따라 WAL 새그먼트 파일명의 첫 8자리도 변경된다.
Timeline History 파일
PITR(Point In Time Recovery) 프로세스가 완료되면 “8자리로 된 새로운 타임라인ID”.history 파일이 생성되고 아래의 정보를 저장하고 있다.
- 복원하는 데 사용된 아카이브 로그의 타임라인ID
- WAL 새그먼티 스위치가 발생한 LSN의 정보
- 타임라인ID가 변경된 이유
$ cat /archive/arc_wal/00000002.history
1 0/A000198 before 2020-1-31 12:05:00.861324+00
or
$ cat /archive/arc_wal/00000003.history
1 0/13000000 no recovery target specified
2 0/21000000 before 2020-1-31 12:05:00.861324+00
00000003.history 파일이 저장한 정보가 의미하는 바는 타임라인ID 값으로 3을 가진 이 데이터베이스 클러스터는 타임라인ID 1과 2를 베이스로 하고 있으며 2020-1-31 12:05:00.861324+00 바로 직전까지 복원하기 위해 0/21000000까지 로그 리플레이를 진행했다는 것이다.
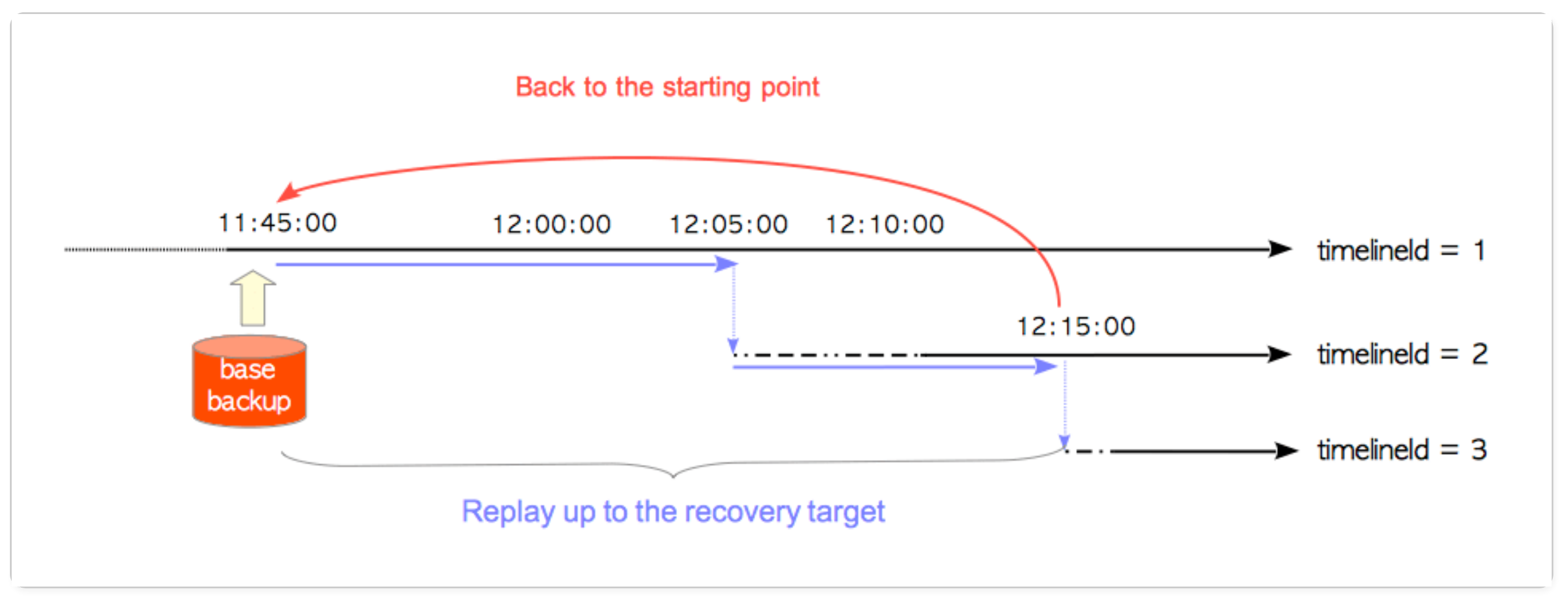
Image from The Internals of PostgreSQL Chapter 10
- restore_command = ‘cp /mnt/server/archivedir/%f %p’
- recovery_target_time = “2020-1-31 12:15:00 GMT”
- recovery_target_timeline = 2
- backup_label 파일에서 checkpoint 위치(Redo Point)를 읽어온다.
- recovery.conf(v12부터는 postgresql.(auto).conf) 파일에서 restore_command, recovery_target_time, and recovery_target_timeline 값들을 읽어온다.
- 지정된 recovery_target_timeline 값에 해당하는 타임라인 히스토리 파일을 읽어들인다.
- Redo Point부터 히스토리2 파일에 명시된 LSN 0/A000198 까지 타임라인ID 값이 1인 아카이브 로그를 가지고 리플레이를 진행한다.
- LSN 0/A000198 지점부터 2020-1-31 12:15:00 직전까지 타임라인ID 값이 2인 아카이브 로그를 가지고 리플레이를 진행한다.
- 복원 프로세스가 완료되면 현재 타임라인ID 값인 2를 3으로 증가시키고 pg_wal와 아카이브 wal 디렉토리에 00000003.history 파일을 생성한다.
PG_RMAN의 소스 코드 분석 및 사용법 알아보기
깃헙에 공개된 소스의 히스토리에 따르면 2009년 12월 일본의 NTT 오픈소스 관련 소프트웨어 연구소 소속의 엔지니어 타카히로 이타가키 씨의 initial 커밋을 시작으로 오늘날까지 유지•보수되고 있는 PG용 백업 솔루션이다.
그 이름에서 유추해볼 수 있듯이 오라클의 RMAN과 유사한 인터페이스를 제공한다. RMAN식의 백업을 사실상의 표준방식(de facto standard)으로 인식하고 있는 DB업계의 많은 DBA들 중에 오라클 중심의 RDBMS 경험에서 탈피하고자 PG에 진입한 엔지니어에게 RMAN과 유사한 인터페이스를 제공함으로써 진입 문턱을 낮췄다는 점에서 소스 코드를 살펴보며 그 작동 원리를 가능하면 자세히 살펴볼 필요가 있다고 판단했다.
설치
깃헙 저장소에서 소스 코드를 직접 받아서 컴파일을 거쳐 설치할 수도 있지만 의존적인 패키지의 부재 문제로 설치가 어려울 수도 있다. 레드햇 계열 리눅스 OS에서 사용가능한 RPM 패키지를 제공하고 있기 때문에 해당 OS 사용자는 RPM 패키지로 설치하는 편을 추천한다.
아래는 RHEL 리눅스 OS 7 버전 & PG 11버전용 PG_RMAN rpm 패키지 설치하는 과정이다.
1. PG_RMAN은 postgresql11-libs 라이브러리가 설치돼 있어서 하므로 커뮤니티 PG에서 제공하는 레드햇용 저장소 등록부터 한다.
yum install -y https://download.postgresql.org/pub/repos/yum/reporpms/EL-7-x86_64/pgdg-redhat-repo-latest.noarch.rpm
2. 저장소 등록을 마친 뒤 postgresql11-libs를 설치한다. (EDB 11 버전을 대상으로 하기에 postgresql11-libs를 설치한다)
yum install -y postgresql11-libs
3. PG_RMAN rpm을 설치한다.
yum install -y https://github.com/ossc-db/pg_rman/releases/download/V1.3.9/pg_rman-1.3.9-1.pg11.rhel7.x86_64.rpm
yum install -y https://github.com/ossc-db/pg_rman/releases/download/V1.3.9/pg_rman-1.3.9-1.pg11.rhel7.x86_64.rpm
Loaded plugins: fastestmirror, ovl
pg_rman-1.3.9-1.pg11.rhel7.x86_64.rpm | 74 kB 00:00:00
Examining /var/tmp/yum-root-s56YUg/pg_rman-1.3.9-1.pg11.rhel7.x86_64.rpm: pg_rman-1.3.9-1.pg11.rhel7.x86_64
Marking /var/tmp/yum-root-s56YUg/pg_rman-1.3.9-1.pg11.rhel7.x86_64.rpm to be installed
Resolving Dependencies
--> Running transaction check
---> Package pg_rman.x86_64 0:1.3.9-1.pg11.rhel7 will be installed
--> Finished Dependency Resolution
Dependencies Resolved
====================================================================================================================================
Package Arch Version Repository Size
====================================================================================================================================
Installing:
pg_rman x86_64 1.3.9-1.pg11.rhel7 /pg_rman-1.3.9-1.pg11.rhel7.x86_64 156 k
Transaction Summary
====================================================================================================================================
Install 1 Package
Total size: 156 k
Installed size: 156 k
Downloading packages:
Running transaction check
Running transaction test
Transaction test succeeded
Running transaction
Installing : pg_rman-1.3.9-1.pg11.rhel7.x86_64 1/1
Verifying : pg_rman-1.3.9-1.pg11.rhel7.x86_64 1/1
Installed:
pg_rman.x86_64 0:1.3.9-1.pg11.rhel7
Complete!
[root@EFM_EDB_11_master /]#
4. 설치에 성공하면 pg_rman 파일은 커뮤니티 PG의 유틸리티가 저장되는 디폴트 디렉토리에 만들어져 있다. EDB 11 버전에서 pg_rman을 사용하려면 /usr/edb/as11/bin (EDB 11 버전의 디폴트 bin 디렉토리)로 이 파일을 옮겨두는 것을 추천한다.
[root@EFM_EDB_11_master /]# ls -al /usr/pgsql-11/bin
total 168
drwxr-xr-x 2 root root 4096 Feb 3 11:21 .
drwxr-xr-x 5 root root 4096 Feb 3 11:21 ..
-rwxr-xr-x 1 root root 160064 Oct 28 17:46 pg_rman
[root@EFM_EDB_11_master /]# cp -p /usr/pgsql-11/bin/pg_rman /usr/edb/as11/bin
사용법
pg_rman [ OPTIONS ] { init |
backup |
restore |
show [ DATE | detail ] |
validate [ DATE ] |
delete DATE |
purge }
pg_rman은 아카이브 모드 사용을 전제하기 때문에 archive_mode -> on, archive_command -> 적절히 설정하고나서 진행해야 한다. 다만 pg_rman에서 내부적으로 postgresql.conf에 정의된 archive_command의 디렉토리 path를 가져오도록 돼 있기 때문에 아카이브 관련 설정은 postgresql.auto.conf가 아니라 postgresql.conf 파일에 해둔다.
pg_hba.conf
환경변수도 설정한다.
PGDATA=/var/lib/pgsql/11/data
PG_CONFIG=/usr/edb/as11/bin/pg_config
BACKUP_PATH=/pg_rman
ARCLOG_PATH=/archive/arc_wal
[enterprisedb@EFM_EDB_11_master data]$ pg_rman init -B /pg_rman -D /var/lib/edb/as11/data -S /var/lib/edb/as11/data/log
INFO: ARCLOG_PATH is set to '/archive/arc_wal'
INFO: SRVLOG_PATH is set to '/var/lib/edb/as11/data/log'
# full backup method
[enterprisedb@EFM_EDB_11_master data]$ pg_rman backup -D /var/lib/edb/as11/data --backup-mode=full -h 172.17.0.2 -p 5444 -d edb -U enterprisedb -v -P -s
INFO: copying database files
INFO: copying archived WAL files
INFO: backup complete
INFO: Please execute 'pg_rman validate' to verify the files are correctly copied.
# incremental backup method
[enterprisedb@EFM_EDB_11_master data]$ pg_rman backup -D /var/lib/edb/as11/data --backup-mode=incremental -h 172.17.0.2 -p 5444 -d edb -U enterprisedb -v -P -s
# 백업 상세 내역 확인하기
[enterprisedb@EFM_EDB_11_master data]$ pg_rman show detail
# 복원과정은 1. stop 2. restore 3. 재시작
[enterprisedb@EFM_EDB_11_master data]$ pg_ctl stop -D $PGDATA -m immediate
[enterprisedb@EFM_EDB_11_master data]$ pg_rman restore
restore_command = 'cp /archive/arc_wal/%f %p'
recovery_target_timeline = '1'
or
recovery_target_time = '03-FEB-20 16:40:26.258447 +09:00'
pg_rman restore --recovery-target-time '03-FEB-20 16:40:26.258447 +09:00'
[enterprisedb@EFM_EDB_11_master data]$ pg_ctl start -D $PGDATA
backup 모드로 백업을 취득 할 때 실행되는 로직의 큰 흐름
pg_rman.c 소스파일의 main 함수를 보면 첫 단계에서 pg_rman을 실행했을 때 유저가 입력한 커맨드를(init, backup, restore, show, validate, delete 등) 먼저 읽어들이고 필수 입력값(BACKUP_PATH 등)의 입력 여부를 체크하는 로직이 시작된다.
if (backup_path == NULL)
ereport(ERROR,
(errcode(ERROR_ARGS),
errmsg("required parameter not specified: BACKUP_PATH (-B, --backup-path)")));
for (; i < argc; i++)
{
if (cmd == NULL)
cmd = argv[i];
else if (pg_strcasecmp(argv[i], "detail") == 0 &&
pg_strcasecmp(cmd, "show") == 0)
show_detail = true;
else if (range1 == NULL)
range1 = argv[i];
else if (range2 == NULL)
range2 = argv[i];
else
ereport(ERROR,
(errcode(ERROR_ARGS),
errmsg("too many arguments")));
}
/* command argument (backup/restore/show/...) is required. */
if (cmd == NULL)
{
help(false);
return HELP;
}
if (backup_path)
{
char path[MAXPGPATH];
/* Check if backup_path is directory. */
struct stat stat_buf;
int rc = stat(backup_path, &stat_buf);
/* If rc == -1, there is no file or directory. So it's OK. */
if(rc != -1 && !S_ISDIR(stat_buf.st_mode))
ereport(ERROR,
(errcode(ERROR_ARGS),
errmsg("-B, --backup-path must be a path to directory")));
join_path_components(path, backup_path, PG_RMAN_INI_FILE);
pgut_readopt(path, options, ERROR_ARGS);
}
입력되었어야 할 값들에 대한 필터링이 끝나면 206행부터 본격적으로 유저가 지정한 pg_rman 커맨드에 따라 do_라는 접두어로 네이밍된 해당 함수가 호출되도록 구성된 로직이 동작하는 것을 끝으로 main 함수가 종료된다.
/* do actual operation */
if (pg_strcasecmp(cmd, "init") == 0)
return do_init();
else if (pg_strcasecmp(cmd, "backup") == 0)
{
pgBackupOption bkupopt;
bkupopt.smooth_checkpoint = smooth_checkpoint;
bkupopt.keep_arclog_files = keep_arclog_files;
bkupopt.keep_arclog_days = keep_arclog_days;
bkupopt.keep_srvlog_files = keep_srvlog_files;
bkupopt.keep_srvlog_days = keep_srvlog_days;
bkupopt.keep_data_generations = keep_data_generations;
bkupopt.keep_data_days = keep_data_days;
bkupopt.standby_host = standby_host;
bkupopt.standby_port = standby_port;
return do_backup(bkupopt);
}
else if (pg_strcasecmp(cmd, "restore") == 0)
return do_restore(target_time, target_xid,
target_inclusive, target_tli_string, is_hard_copy);
else if (pg_strcasecmp(cmd, "show") == 0)
return do_show(&range, show_detail, show_all);
else if (pg_strcasecmp(cmd, "validate") == 0)
return do_validate(&range);
else if (pg_strcasecmp(cmd, "delete") == 0)
return do_delete(&range, force);
else if (pg_strcasecmp(cmd, "purge") == 0)
return do_purge();
else
ereport(ERROR,
(errcode(ERROR_ARGS),
errmsg("invalid command \"%s\"", cmd)));
return 0;
backup 커맨드가 호출된 이후 do_backup의 내부 로직
backup.c 파일이 backup 커맨드가 선택되었을 때 실행되는 로직을 담고 있다. bkupopt 변수에 담겨 넘어온 옵션값들을 함수 내부에서 리패킹하고 필수 옵션 값들의 유무를 확인하는 로직부터 시작한다. 필터링 과정이 끝나면 966행부터 data directory, 아카이브 WAL, 서버 로그를 백업하는 로직이 등장한다.
/* backup data */
files_database = do_backup_database(backup_list, bkupopt);
/* backup archived WAL */
files_arclog = do_backup_arclog(backup_list);
/* backup serverlog */
files_srvlog = do_backup_srvlog(backup_list);
do_backup_database 함수의 정의는 backup.c 파일의 80행부터 나온다. 이 함수에서도 내부적으로 필수 입력값의 유무를 체크한 다음 pg_start_backup이라는 함수가 호출되는 로직이다. (start 이후 데이터 파일을 백업하는 로직이 끝나면 265행에서 pg_stop_backup이 실행된다)
/* notify start of backup to PostgreSQL server */
time2iso(label, lengthof(label), current.start_time);
strncat(label, " with pg_rman", lengthof(label));
pg_start_backup(label, smooth_checkpoint, ¤t);
pg_start_backup
pg_start_backup(const char *label, bool smooth, pgBackup *backup)
{
PGresult *res;
const char *params[3];
params[0] = label;
elog(DEBUG, "executing pg_start_backup()");
/*
* Establish new connection to send backup control commands. The same
* connection is used until the current backup finishes which is required
* with the new non-exclusive backup API as of PG version 9.6.
*/
reconnect();
/* Assumes PG version >= 8.4 */
/* 2nd argument is 'fast' (IOW, !smooth) */
params[1] = smooth ? "false" : "true";
/* 3rd argument is 'exclusive' (assumes PG version >= 9.6) */
params[2] = "false";
res = execute("SELECT * from pg_walfile_name_offset(pg_start_backup($1, $2, $3))", 3, params);
if (backup != NULL)
get_lsn(res, &backup->tli, &backup->start_lsn);
elog(DEBUG, "backup start point is (WAL file: %s, xrecoff: %s)",
PQgetvalue(res, 0, 0), PQgetvalue(res, 0, 1));
PQclear(res);
}
pg_stop_backup
static parray *
pg_stop_backup(pgBackup *backup)
{
parray *result = parray_new();
pgFile *file;
PGresult *res;
char *backup_lsn;
char *backuplabel = NULL;
int backuplabel_len;
char *tblspcmap = NULL;
int tblspcmap_len;
const char *params[1];
elog(DEBUG, "executing pg_stop_backup()");
/*
* Non-exclusive backup requires to use same connection as the one
* used to issue pg_start_backup(). Remember we did not disconnect
* in pg_start_backup() nor did we lose our connection when issuing
* commands to standby.
*/
Assert(connection != NULL);
/* Remove annoying NOTICE messages generated by backend */
res = execute("SET client_min_messages = warning;", 0, NULL);
PQclear(res);
params[0] = "false";
res = execute("SELECT * FROM pg_stop_backup($1)", 1, params);
if (res == NULL || PQntuples(res) != 1 || PQnfields(res) != 3)
ereport(ERROR,
(errcode(ERROR_PG_COMMAND),
errmsg("result of pg_stop_backup($1) is invalid: %s",
PQerrorMessage(connection))));
backup_lsn = PQgetvalue(res, 0, 0);
backuplabel = PQgetvalue(res, 0, 1);
backuplabel_len = PQgetlength(res, 0, 1);
tblspcmap = PQgetvalue(res, 0, 2);
tblspcmap_len = PQgetlength(res, 0, 2);
Assert(backuplabel_len > 0);
file = write_stop_backup_file(backup, backuplabel, backuplabel_len,
PG_BACKUP_LABEL_FILE);
parray_append(result, (void *) file);
if (tblspcmap_len > 0)
{
file = write_stop_backup_file(backup, tblspcmap, tblspcmap_len,
PG_TBLSPC_MAP_FILE);
parray_append(result, (void *) file);
}
params[0] = backup_lsn;
wait_for_archive(backup,
"SELECT * FROM pg_walfile_name_offset($1)",
1, params);
/* Done with the connection. */
disconnect();
return result;
}
-
PG의 네이티브 백업 API인 pg_start_backup 함수 호출만으로는 불가능하고 이 API를 기반으로 만들어진 써드파티 백업솔루션인 EDB사의 BART나 2ndQuadrant사의 BARMAN 또는 PG_RMAN 등을 사용하면 가능. ↩